專注Java教育14年
全國咨詢/投訴熱線:400-8080-105
更新時間:2022-07-13 10:35:46 來源:動力節(jié)點 瀏覽2094次
在MySQL教程中會學到分庫分表,下面就由動力節(jié)點小編來給大家進行詳細介紹。
數(shù)據(jù)庫擴展解決了什么問題?
做熱備份,保證多活,方便故障切換
負載均衡、讀寫分離
1.主從架構(gòu):Master-Slaves
在實際應(yīng)用場景中,MySQL 復制 90% 以上都是一個 Master 復制到一個或者多個 Slave 的架構(gòu)模式。
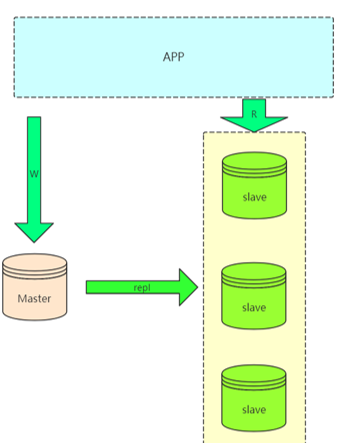
缺點:
master 不能停機,停機就不能接收寫請求。
slave 過多會出現(xiàn)延遲。
由于 master 需要進行常規(guī)維護停機了,那必須要把一個slave提成master,會存在某一個 slave 提成 master 后,存在當前 master 和掛掉之前的 master 數(shù)據(jù)不一致的情況,并且之前 master 并沒有保存當前 master 節(jié)點的 binlog 文件和 pos 位置。
2.雙主架構(gòu):Master-Master
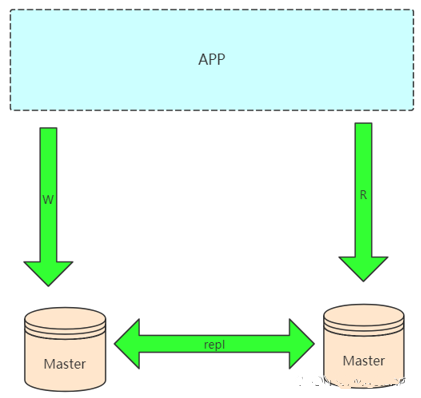
配合第三方的工具,比如 keepalived 輕松做到 IP 的漂移,當一個 master 掛掉后,請求轉(zhuǎn)移到另一個 master。
3.級聯(lián)復制架構(gòu):Master-Slaves-Slaves…
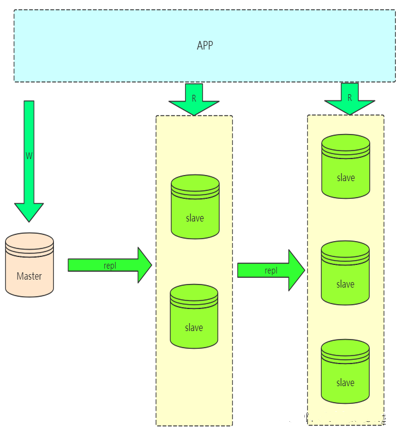
如果讀壓力加大,就需要更多的 slave 來解決,但是如果 slave 的復制全部從 master 復制,勢必會加大 master 的復制 IO 的壓力,所以就出現(xiàn)了級聯(lián)復制,減輕 master 壓力。缺點是 slave 延遲更加大了。
4.雙主與級聯(lián)復制架構(gòu):Master-Master-Slaves
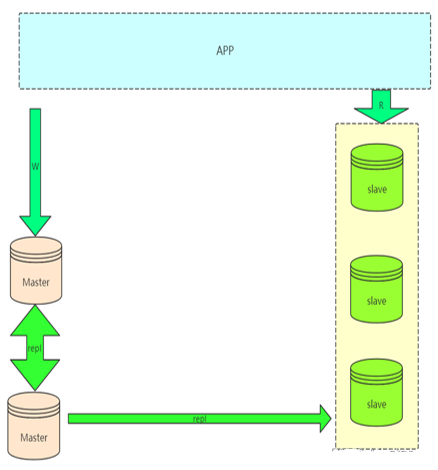
這樣解決了單點 master 的問題,解決了 slave 級聯(lián)延遲的問題。
5.復制機制
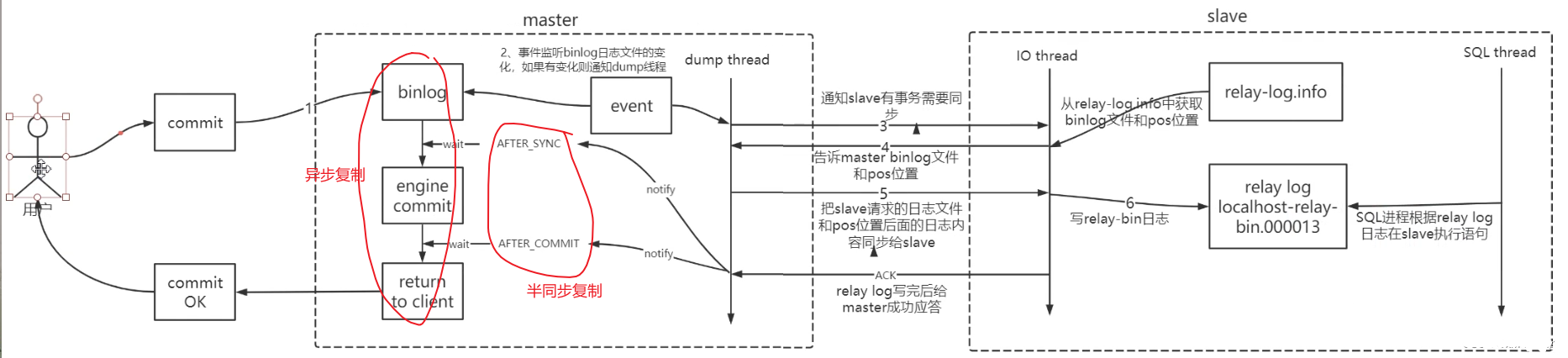
MySQL 復制支持異步復制、半同步復制:異步復制時不需要等待 slave 返回。
半同步復制失敗后會切換為異步。
6.主從復制配置
master配置
server-id=135
log-bin=mysql-bin
auto_increment_increment=2
auto_increment_offset=1
lower_case_table_names=1
#binlog-do-db=mstest //要同步的mstest數(shù)據(jù)庫,要同步多個數(shù)據(jù)庫
#binlog-ignore-db=mysql //要忽略的數(shù)據(jù)庫
slave配置
server-id=133
log-bin=mysql-bin
auto-increment-increment=2
auto-increment-offset=2
lower_case_table_names=1
#replicate-do-db = wang #需要同步的數(shù)據(jù)庫
#binlog-ignore-db = mysql
#binlog-ignore-db = information_schema
在 master mysql 添加權(quán)限
GRANT REPLICATION SLAVE,FILE,REPLICATION CLIENT ON *.* TO 'repluser'@'%' IDENTIFIED BY '123456';
FLUSH PRIVILEGES;
在 master 上查看 master 的二進制日志
show master status;

在 slave 中設(shè)置 master 的信息
change master to master_host='192.168.88.135',master_port=3307,master_user='repluser',master_password='Jack@123456',master_log_file='mysql-bin.000001',master_log_pos=154;
開啟 slave,啟動 SQL 和 IO 線程
start slave;
查看 slave 的狀態(tài)
show slave status\G
查看二進制日志是否開啟
show global variables like "%log%";
查看進程信息
SHOW PROCESSLIST;
允許root遠程連接
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'youpassword' WITH GRANT OPTION;
FLUSH PRIVILEGES;
7.半同步復制配置
加載 lib,所有主從節(jié)點都要配置
主庫:install plugin rpl_semi_sync_master soname ‘semisync_master.so’;
從庫:install plugin rpl_semi_sync_slave soname ‘semisync_slave.so’;
查看,確保所有節(jié)點都成功加載。show plugins;
啟用半同步
先啟用從庫上的參數(shù),最后啟用主庫的參數(shù)。
從庫:set global rpl_semi_sync_slave_enabled = {0|1}; # 1:啟用,0:禁止
主庫:
set global rpl_semi_sync_master_enabled = {0|1}; # 1:啟用,0:禁止
set global rpl_semi_sync_master_timeout = 10000; # 單位為ms
數(shù)據(jù)切分指通過某種特定的條件,將我們存放在同一個數(shù)據(jù)庫中的數(shù)據(jù)分散存放到多個數(shù)據(jù)庫(主機)上面,以達到分散單臺設(shè)備負載的效果。
數(shù)據(jù)切分分為兩種:
垂直切分
水平切分
1.數(shù)據(jù)庫垂直切分
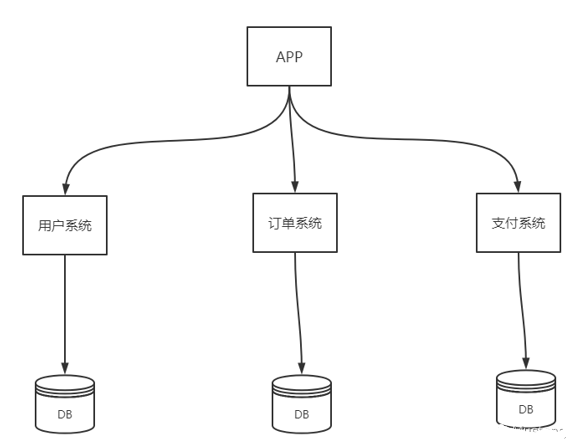
垂直切分的優(yōu)點:
數(shù)據(jù)庫的拆分簡單明了,拆分規(guī)則明確;
應(yīng)用程序模塊清晰明確,整合容易;
數(shù)據(jù)維護方便易行,容易定位;
垂直切分缺點:
跨庫 join
代碼要重構(gòu),會有分布式事務(wù)問題
跨庫分頁問題。
部分表關(guān)聯(lián)無法在數(shù)據(jù)庫級別完成,需要在程序中完成,存在跨庫 join 的問題,對于這類的表,就需要去做平衡,是數(shù)據(jù)庫讓步業(yè)務(wù),共用一個數(shù)據(jù)源,還是分成多個庫,業(yè)務(wù)之間通過接口來做調(diào)用;在系統(tǒng)初期,數(shù)據(jù)量比較少,或者資源有限的情況下,會選擇共用數(shù)據(jù)源,但是當數(shù)據(jù)發(fā)展到了一定的規(guī)模,負載很大的情況,就需要必須去做分割。
對于訪問極其頻繁且數(shù)據(jù)量超大的表仍然存在性能瓶頸,不一定能滿足要求。
事務(wù)處理相對更為復雜。
切分達到一定程度之后,擴展性會遇到限制。
過多切分可能會帶來系統(tǒng)過渡復雜而難以維護。
2.數(shù)據(jù)庫水平拆分
水平拆分不是將表做分類,而是按照某個字段的某種規(guī)則來分散到多個庫之中,每個表中包含一部分數(shù)據(jù)。簡單來說,我們可以將數(shù)據(jù)的水平切分理解為是按照數(shù)據(jù)行的切分,就是將表中的某些行切分到一個數(shù)據(jù)庫,而另外的某些行又切分到其他的數(shù)據(jù)庫中。
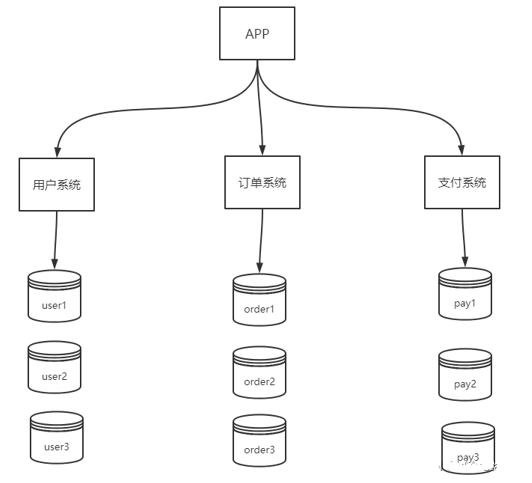
水平切分的優(yōu)點:
表關(guān)聯(lián)基本能夠在數(shù)據(jù)庫端全部完成;
不會存在某些超大型數(shù)據(jù)量和高負載的表遇到瓶頸的問題;
應(yīng)用程序端整體架構(gòu)改動相對較少;
事務(wù)處理相對簡單;
只要切分規(guī)則能夠定義好,基本上較難遇到擴展性限制;
水平切分的缺點:
切分規(guī)則相對更為復雜,很難抽象出一個能夠滿足整個數(shù)據(jù)庫的切分規(guī)則;
后期數(shù)據(jù)的維護難度有所增加,人為手工定位數(shù)據(jù)更困難;
應(yīng)用系統(tǒng)各模塊耦合度較高,可能會對后面數(shù)據(jù)的遷移拆分造成一定的困難。
跨節(jié)點合并排序分頁問題
多數(shù)據(jù)源管理問題
以上就是關(guān)于“MySQL的分庫分表框架”的介紹,大家如果想了解更多相關(guān)知識,可以關(guān)注一下動力節(jié)點的MySQL視頻教程,里面的課程內(nèi)容細致全面,通俗易懂,很適合沒有基礎(chǔ)的小伙伴學習,希望對大家能夠有所幫助哦。

官方微信

官方抖音










 Java實驗班
Java實驗班
 Java就業(yè)班
Java就業(yè)班
 Java夜校直播班
Java夜校直播班
 Java在職加薪班
Java在職加薪班
 Java架構(gòu)師班
Java架構(gòu)師班







 京公網(wǎng)安備 11030102010736號
京公網(wǎng)安備 11030102010736號