專注Java教育14年
全國咨詢/投訴熱線:400-8080-105
更新時間:2022-12-21 11:17:18 來源:動力節點 瀏覽1200次
大家在學習Java的時候都會學到Redis教程,下面我們來了解一下Redis與數據庫同步問題的解決方法。
比如說Session這種訪問非常頻繁的數據,就適合采用這種方案;當然了,既然沒有涉及到數據庫,那么也就不會存在一致性問題;
讀操作
目前的讀操作有個固定的套路,如下:
客戶端請求服務器的時候,發現如果服務器的緩存中存在,則直接取服務器的;
如果緩存中不存在,則去請求數據庫,并且將數據庫計算出來的數據回填給緩存;
返回數據給客戶端;
寫操作
各種情況會導致數據庫和緩存出現不一致的情況,這就是緩存和數據庫的雙寫一致性問題;
目前緩存存在三種策略,分別是
Cache Aside 更新策略:同時更新緩存和數據庫;
Read/Write Through 更新策略:先更新緩存,緩存負責同步更新數據庫;
Write Behind Caching 更新策略:先更新緩存,緩存定時異步更新數據庫;
三種策略各有優缺點,可以根據業務場景使用;
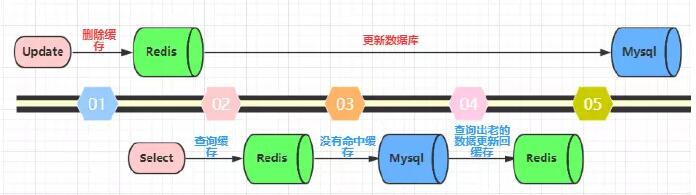
該策略大概的流程就是請求過來時先從緩存中取,如果命中緩存的話,則直接返回讀取的數據;相反如果沒有命中的話,接著會從數據庫中成功獲取到數據后,再去清除緩存中的數據;具體流程圖如下:
但是以上在某些特殊的情況下是存在問題:
問題1:先更新數據庫,后更新緩存
兩個線程在高并發的情況下就會可能出現數據臟讀的情況:
線程A執行寫操作,成功更新數據庫;
線程B同樣執行和線程A一樣的操作,但是在線程A執行更新緩存的過程中,線程B更新了新的數據庫數據到緩存中;
線程A在線程B全部操作完成以后才將相對老的數據又更新到了緩存中;
問題2:先刪除緩存,后更新數據庫
同樣的,在高并發場景下同樣會出現臟讀的情況:
線程A成功刪除了緩存,等待更新數據庫;
線程B進行讀操作,由于此時緩存已經被刪除了,因此線程B重新從數據庫中獲取老的數據并且更新到了緩存中;
線程A在線程B完成了整個的讀操作以后,才更新數據庫,此時緩存中的數據依舊是老的數據;
問題3:先更新數據庫,后刪除緩存
目前這是比較普遍的操作,即使它還是有可能會出現臟讀的情況:
線程A進行讀操作,此時正好沒有命中緩存,接著請求數據庫;
線程B進行寫操作,在線程A沒有從數據庫中獲取到數據之前,把數據寫入到數據庫中,并且還成功刪除了緩存;
線程A在線程B完成了整個的寫操作以后,才將相對老的數據更新到緩存中;
但是以上的情況比較不會出現,這是因為上述情況需要滿足線程A的讀操作要慢于線程B的寫操作,但是在現實過程中,讀操作通常都是要快于寫操作得多的,但是為了避免發生以上的情況,通常都是要給緩存加上一個過期的時間;
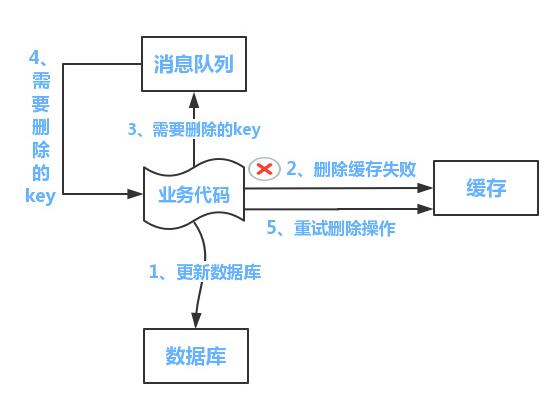
但是設想一下,如果上面的刪除緩存失敗了怎么辦呢,這樣顯然會導致數據臟讀的情況,我覺得方案如下:
設置緩存的過期時間(必須要做);
提供一個保障重試機制,將哪些刪除失敗的key提供給消息隊列去消費;
從消息隊列取出這些key再次進行刪除,失敗再次加入到消息隊列中,超過一定次數以上則人工介入;
但是以上情況需要在業務代碼中進行操作,顯然得需要進行解耦;
目前我們公司就是使用該方案,具體過程為在更新數據庫數據的時候,數據庫會以binlog日志的形式保存下來,通過canal開源軟件將binlog解析成程序語言可以解析的地步,接著訂閱程序獲取到這些數據以后,嘗試刪除緩存操作,如果操作失敗的話,則將其加入到消息隊列中,重復消費,當刪除操作的失敗次數到達一定的次數以后,還是得人工介入。
該模式下,程序只需要維護緩存即可,數據庫的同步工作交由緩存來同步更新;
該策略具體又分為兩種:
Read Through:在查詢的過程中更新緩存;
Write Through:在寫操作的過程中如果命中緩存,則直接更新緩存,數據庫則由緩存自己同步去更新;
該策略只更新緩存,不會立馬更新數據庫,只會在一定的時間異步的批量去操作數據庫;這樣的好處在于直接操作緩存,效率極高,并且操作數據是異步的,還可以將多次的操作數據庫語句合并到一個事務中一起提交,因此效率很客觀;
但是,該策略沒有辦法做到數據強一致性,并且實現邏輯相對是比較復雜的,因為它需要確認哪些是需要更新到數據庫的,哪些是僅僅想要存儲在緩存中的;
目前通常使用的是第一種策略中的先更新數據庫,后更新緩存;其他的相較比起來實現都比較復雜;
最后想說的是,緩存本來就是為了犧牲強一致性來提高性能的,所以肯定會存在一定的延遲時間,我們只需要保證最終的數據一致性即可;
 Java實驗班
Java實驗班
0基礎 0學費 15天面授
 Java就業班
Java就業班
有基礎 直達就業
 Java夜校直播班
Java夜校直播班
業余時間 高薪轉行
 Java在職加薪班
Java在職加薪班
工作1~3年,加薪神器
 Java架構師班
Java架構師班
工作3~5年,晉升架構
提交申請后,顧問老師會電話與您溝通安排學習

官方微信

官方抖音

















 京公網安備 11030102010736號
京公網安備 11030102010736號