專注Java教育14年
全國咨詢/投訴熱線:400-8080-105
更新時間:2022-12-02 10:48:28 來源:動力節(jié)點 瀏覽4039次
Tess4J簡介
Tesseract-OCR支持中文識別,并且開源和提供全套的訓練工具,是快速低成本開發(fā)的首選。而Tess4J則是Tesseract在Java PC上的應用。在英文和數字識別中性能還是不錯的,但是在中文識別中,無論速度還是識別率還是較弱,建議有條件的話,針對場景進行訓練,會獲得較好結果。
Tess4J的使用
1.Maven導入依賴
<dependencies>
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.2.1</version>
</dependency>
</dependencies>
2.添加Tessdata語言庫
網址:mirrors / tesseract-ocr / tessdata · GitCode
下載下面這個字庫文件:
【注意】路徑中不得有中文

3.準備圖片資源
【注意】路徑中不得有中文
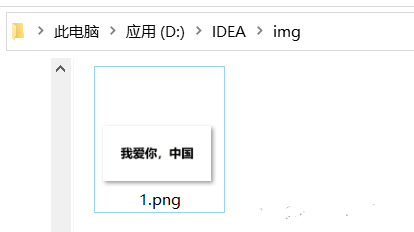
4.編寫代碼
package cn.zcj;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
public class tess4jDemo {
public static void main(String[] args) {
//圖片路徑
String path = "D:\\IDEA\\img\\1.png";
//語言位置
String languagePath = "D:\\IDEA\\tess4j";
File file = new File(path);
Tesseract instance = new Tesseract();
//設置訓練庫位置
instance.setDatapath(languagePath);
//chi_sim:簡體中文,eng根據需求選擇語言庫
instance.setLanguage("chi_sim");
String result = null;
try{
result = instance.doOCR(file);
}catch (TesseractException e){
e.printStackTrace();
}
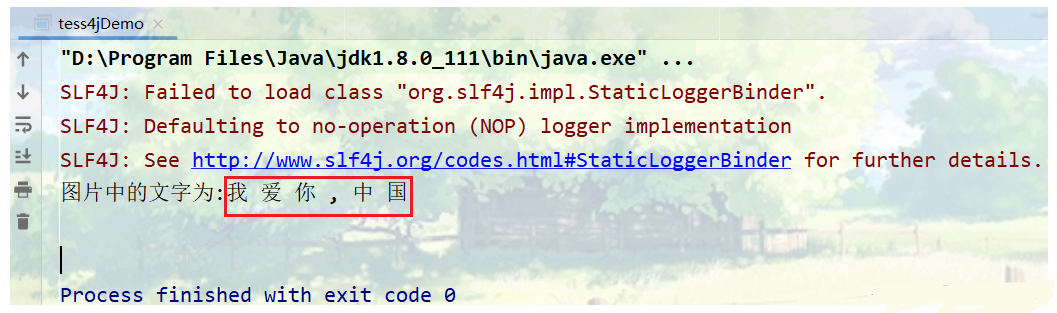
System.out.println("圖片中的文字為:"+result);
}
}
輸出結果為:

官方微信

官方抖音










 Java實驗班
Java實驗班
 Java就業(yè)班
Java就業(yè)班
 Java夜校直播班
Java夜校直播班
 Java在職加薪班
Java在職加薪班
 Java架構師班
Java架構師班







 京公網安備 11030102010736號
京公網安備 11030102010736號