JDBC的全稱是Java DataBase Connection,也就是Java數(shù)據(jù)庫連接,我們可以?它來操作關(guān)系型數(shù)據(jù)庫。JDBC接?及相關(guān)類在java.sql 包和javax.sql包?。我們可以?它來連接數(shù)據(jù)庫,執(zhí)?SQL查詢,存儲過程,并處理返回的結(jié)果。
JDBC接?讓Java程序和JDBC驅(qū)動實(shí)現(xiàn)了松耦合,使得切換不同的數(shù)據(jù)庫變得更加簡單。
1.com.mysql.cj.jdbc.Driver是Driver驅(qū)動所在的位置,加載驅(qū)動
2.Class.forName()是一個(gè)反射,但是他沒有返回一個(gè)Class對象,因?yàn)槲覀儾恍枰?br />
這是Driver的代碼:
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
public Driver() throws SQLException {
}
static {
try {
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}
}
}
它除了構(gòu)造方法,就只有一個(gè)靜態(tài)代碼塊,當(dāng)我們反射進(jìn)行的時(shí)候,這個(gè)類就開始初始化,他的靜態(tài)代碼塊內(nèi)容就已經(jīng)被執(zhí)行了,我們真正需要的是DriverManager.registerDriver(new Driver());這一行代碼
是一個(gè)工廠類,我們通過它來創(chuàng)建數(shù)據(jù)庫連接,當(dāng)JDBC的Driver類被加載進(jìn)來時(shí),它會自己注冊到DriverManager類里面
1.注冊驅(qū)動
2.獲取連接
3.創(chuàng)建一個(gè)Statement語句對象
4.執(zhí)行SQL語句
5.處理結(jié)果集
6.關(guān)閉資源
1.PreparedStatement 繼承于 Statement,Statement 一般用于執(zhí)行固定的沒有參數(shù)的SQL。2.PreparedStatement 一般用于執(zhí)行有?參數(shù)預(yù)編譯的SQL語句。可以防止SQL注入,安全性高于Statement。3.CallableStatement適用于執(zhí)行存儲過程。
1)Statement的execute(String query)?法?來執(zhí)?任意的SQL查詢,如果查詢的結(jié)果是?個(gè)ResultSet,這個(gè)?法就返回true。如果結(jié)果不是ResultSet,?如insert或者update查詢,它就會返回false。
2)Statement的executeQuery(String query)接??來執(zhí)?select查詢,并且返回ResultSet。即使查詢不到記錄返回的ResultSet也不會為null。我們通常使?executeQuery來執(zhí)?查詢語句,這樣的話如果傳進(jìn)來的是insert或者update語句的 話,它會拋出錯(cuò)誤信息為“executeQuery method can not be used for update”的java.util.SQLException。
3)Statement的executeUpdate(String query)?法?來執(zhí)?insert或者update/delete(DML)語句。
4)只有當(dāng)你不確定是什么語句的時(shí)候才應(yīng)該使?execute()?法,否則應(yīng)該使?executeQuery或者executeUpdate?法。
最好的辦法是利用sql語句進(jìn)行分頁,這樣每次查詢出的結(jié)果集中就只包含某頁的數(shù)據(jù)內(nèi)容。
sql語句分頁,不同的數(shù)據(jù)庫下的分頁方案各不一樣,假設(shè)一共有38條數(shù)據(jù),每頁有10條數(shù)據(jù),查詢第3頁的數(shù)據(jù),下面是主流的三種數(shù)據(jù)庫的分頁sql:
Oracle:
select * from
(select *,rownum as tempid from student ) t
where t.tempid between 20 and 30;mysql:
select * from students limit 20,10;sql server:
select top 10 * from students where id not in?
(select top 20 id from students order by id)?
order by id;事務(wù)是作為單個(gè)邏輯?作單元執(zhí)?的?系列操作,?個(gè)邏輯?作單元必須有四個(gè)屬性,稱為原?性、?致性、隔離性和持久性(ACID) 屬性,只有這樣才能成為?個(gè)事務(wù) 。JDBC處理事務(wù)有如下操作:
conn.setAutoComit(false);設(shè)置提交?式為??提交。
conn.commit()提交事務(wù)。
conn.rollback()回滾事務(wù)。
提交與回滾只選擇?個(gè)執(zhí)?。正常情況下提交事務(wù),如果出現(xiàn)異常,則回滾。
數(shù)據(jù)庫連接是?種關(guān)鍵的有限的昂貴的資源,對數(shù)據(jù)庫連接的管理能顯著影響到整個(gè)應(yīng)?程序的伸縮性和健壯性,影響到程序 的性能指標(biāo)。數(shù)據(jù)庫連接池正是針對這個(gè)問題提出來的。
數(shù)據(jù)庫連接池負(fù)責(zé)分配、管理和釋放數(shù)據(jù)庫連接,它允許應(yīng)?程序重復(fù)使??個(gè)現(xiàn)有的數(shù)據(jù)庫連接,?不是重新建??個(gè);釋放空閑時(shí)間超過最?空閑時(shí)間的數(shù)據(jù)庫連接來避免因?yàn)闆]有釋放數(shù)據(jù)庫連接?引起的數(shù)據(jù)庫連接遺漏。這項(xiàng)技術(shù)能明顯提?對數(shù)據(jù)庫操作的性能。
數(shù)據(jù)庫連接池在初始化時(shí)將創(chuàng)建?定數(shù)量的數(shù)據(jù)庫連接放到連接池中,這些數(shù)據(jù)庫連接的數(shù)量是由最?數(shù)據(jù)庫連接數(shù)來設(shè)定的。?論這些數(shù)據(jù)庫連接是否被使?,連接池都將?直保證?少擁有這么多的連接數(shù)量。連接池的最?數(shù)據(jù)庫連接數(shù)量限定了這個(gè)連接池能占有的最?連接數(shù),當(dāng)應(yīng)?程序向連接池請求的連接數(shù)超過最?連接數(shù)量時(shí),這些請求將被加?到等待隊(duì)列中。
橋接模式,首先DriverManager獲得Connection是通過反射和類加載機(jī)制從數(shù)據(jù)庫驅(qū)動包的driver中拿到連接,所以這里真正參與橋接模式的是driver,而DriverManager和橋接模式?jīng)]有關(guān)系,DriverManager只是對driver的一個(gè)管理器。而我們作為使用者只去關(guān)心Connection,不會去關(guān)心driver,因?yàn)槲覀兊牟僮鞫际峭ㄟ^操作Connection來實(shí)現(xiàn)的。這樣分析下來這個(gè)橋接就清晰了邏輯——java.sql.Driver作為抽象橋類,而驅(qū)動包如com.mysql.jdbc.Driver具體的實(shí)現(xiàn)橋接類,而Connection是被橋接的對象。
默認(rèn)情況下,我們創(chuàng)建的數(shù)據(jù)庫連接,是工作在自動提交的模式下的。這意味著只要我們執(zhí)行完一條查詢語句,就會自動進(jìn)行提交。因此我們的每條查詢,實(shí)際上都是一個(gè)事務(wù),如果我們執(zhí)行的是DML或者DDL,每條語句完成的時(shí)候,數(shù)據(jù)庫就已經(jīng)完成修改了。有的時(shí)候我們希望由一組SQL查詢組成一個(gè)事務(wù),如果它們都執(zhí)行OK我們再進(jìn)行提交,如果中途出現(xiàn)異常了,我們可以進(jìn)行回滾。
JDBC接口提供了一個(gè)setAutoCommit(boolean flag)方法,我們可以用它來關(guān)閉連接自動提交的特性。我們應(yīng)該在需要手動提交時(shí)才關(guān)閉這個(gè)特性,不然的話事務(wù)不會自動提交,每次都得手動提交。數(shù)據(jù)庫 通過表鎖來管理事務(wù),這個(gè)操作非常消耗資源。因此我們應(yīng)當(dāng)完成操作后盡快的提交事務(wù)。在這里有更多關(guān)于事務(wù)的示例程序。
CLOB意思是Character Large OBjects,字符大對象,它是由單字節(jié)字符組成的字符串?dāng)?shù)據(jù),有自己專門的代碼頁。這種數(shù)據(jù)類型適用于存儲超長的文本信息,那些可能會超出標(biāo)準(zhǔn)的VARCHAR數(shù)據(jù)類型長度限制(上限是32KB)的文本。
BLOB是Binary Larget OBject,它是二進(jìn)制大對象,由二進(jìn)制數(shù)據(jù)組成,沒有專門的代碼頁。它能用于存儲超過VARBINARY限制(32KB)的二進(jìn)制數(shù)據(jù)。這種數(shù)據(jù)類型適合存儲圖片,聲音,圖形,或者其它業(yè)務(wù)程序特定的數(shù)據(jù)。
每個(gè)類都有一個(gè) Class 對象,包含了與類有關(guān)的信息。當(dāng)編譯一個(gè)新類時(shí),會產(chǎn)生一個(gè)同名的 .class 文件,該文件內(nèi)容保存著 Class 對象。類加載相當(dāng)于 Class 對象的加載,類在第一次使用時(shí)才動態(tài)加載到 JVM 中。也可以使用 Class.forName,這種方式來控制類的加載,該方法會返回一個(gè) Class 對象。
反射可以提供運(yùn)行時(shí)的類信息,并且這個(gè)類可以在運(yùn)行時(shí)才加載進(jìn)來,甚至在編譯時(shí)期該類的 .class 不存在也可以加載進(jìn)來。Class 和 java.lang.reflect 一起對反射提供了支持,java.lang.reflect 類庫主要包含了以下三個(gè)類:
(1)Field :可以使用 get() 和 set() 方法讀取和修改 Field 對象關(guān)聯(lián)的字段;
(2)Method :可以使用 invoke() 方法調(diào)用與 Method 對象關(guān)聯(lián)的方法;
(3)Constructor :可以用 Constructor 創(chuàng)建新的對象。
應(yīng)用舉例:工廠模式,使用反射機(jī)制,根據(jù)全限定類名獲得某個(gè)類的 Class 實(shí)例。
反射是用來描述類的信息的。對于任意一個(gè)類,都能夠知道這個(gè)類的所有屬性和方法;對于任意一個(gè)對象,都能夠調(diào)用它的任意一個(gè)方法和屬性;這種動態(tài)獲取的信息以及動態(tài)調(diào)用對象的方法的功能稱為 Java 語言的反射機(jī)制。
class:用來描述類本身
Packge:用來描述類所屬的包
Field:用來描述類中的屬性
Method:用來描述類中的方法
Constructor:用來描述類中的構(gòu)造方法
Annotation:用來描述類中的注解
1)Class clazz=class.forName("包名.類名")
2)Class clazz=類名.class;
3)Class clazz=對象.getClass();
(1)獲取類的權(quán)限修飾符--------->int result=getModifiers();
(2)獲取名字------------>string name=clazz.getName();
(3)獲取包名------------>Packge p=clazz.getPackge();
(4)尋找clazz中無參數(shù)構(gòu)造方法:Clazz.getConstructor([String.class]);
執(zhí)行構(gòu)造方法創(chuàng)建對象:Con.newInstance([參數(shù)]);
(5)Field c=cls.getFields():獲得某個(gè)類的所有的公共(public)的字段,包括父類中的字段。
Field c=cls.getDeclaredFields():獲得某個(gè)類的所有聲明的字段,即包括public、private和 proteced,但是不包括父類的聲明字段。
(1)反射得經(jīng)典用法就是在xml或者properties配置文件中,然后在java類里面區(qū)解析這些內(nèi)容,得到一個(gè)字符串,然后通過反射機(jī)制,通過這些字符串獲得某個(gè)類得class實(shí)例,這樣的話就可以動態(tài)的配置一些東西,而不需要每次都重新去new,要改的話也是直接改配置文件,代碼維護(hù)起來方便很多。
(2)當(dāng)你在做一個(gè)軟件開發(fā)的插件的時(shí)候,你連插件的類型名稱都不知道,你怎么實(shí)例化這個(gè)對象呢?因?yàn)槌绦蚴侵С植寮模ǖ谌降模陂_發(fā)的時(shí)候并不知道 。所以無法在代碼中 New出來 ,但反射可以,通過反射,動態(tài)加載程序集,然后讀出類,檢查標(biāo)記之后再實(shí)例化對象,就可以獲得正確的類實(shí)例。
(3)在編碼階段不知道那個(gè)類名,要在運(yùn)行期從配置文件讀取類名, 這時(shí)候就沒有辦法硬編碼new ClassName(),而必須用到反射才能創(chuàng)建這個(gè)對象.反射的目的就是為了擴(kuò)展未知的應(yīng)用。比如你寫了一個(gè)程序,這個(gè)程序定義了一些接口,只要實(shí)現(xiàn)了這些接口的dll都可以作為插件來插入到這個(gè)程序中。那么怎么實(shí)現(xiàn)呢?就可以通過反射來實(shí)現(xiàn)。就是把dll加載進(jìn)內(nèi)存,然后通過反射的方式來調(diào)用dll中的方法。很多工廠模式就是使用的反射。
getSimpleName:只獲取類名
getName:類的全限定名,jvm中Class的表示,可以用于動態(tài)加載Class對象,例如Class.forName。
getCanonicalName:返回更容易理解的表示,主要用于輸出(toString)或log打印,大多數(shù)情況下和getName一樣,但是在內(nèi)部類、數(shù)組等類型的表示形式就不同了。
可以;必須只有一個(gè)類名與文件名相同。
byte 的取值范圍是 -128 -> 127 之間,一共是 256 位。一個(gè) byte 類型在計(jì)算機(jī)中占據(jù)一個(gè)字節(jié),那么就是 8 bit,所以最大就是 2^7 = 1111 1111。
Java 中用補(bǔ)碼來表示二進(jìn)制數(shù),補(bǔ)碼的最高位是符號位,最高位用 0 表示正數(shù),最高位 1 表示負(fù)數(shù),正數(shù)的補(bǔ)碼就是其本身,由于最高位是符號位,所以正數(shù)表示的就是 0111 1111 ,也就是 127。最大負(fù)數(shù)就是 1111 1111,這其中會涉及到兩個(gè) 0 ,一個(gè) +0 ,一個(gè) -0 ,+0 歸為正數(shù),也就是 0 ,-0 歸為負(fù)數(shù),也就是 -128,所以 byte 的范圍就是 -128 – 127。
在最外層循環(huán)前加一個(gè)標(biāo)記如outfor,然后用break outfor;可以跳出多重循環(huán)。例如以下代碼:
public class TestBreak {
????public static void main(String[] args) {
????????outfor: for (int i = 0; i < 10; i++){
???????? for (int j = 0; j < 10; j++){
???????? if (j == 5){
???????????? break outfor;
???????????? }
???????????? System.out.println("j = " + j);
???????? }
???? }
????}
}運(yùn)行結(jié)果如下所示:
j = 0
j = 1
j = 2
j = 3
j = 4早期的 JDK 中,switch(expr)中,expr 可以是 byte、short、char、int。從 1.5 版開始,Java 中引入了枚舉類型(enum),expr 也可以是枚舉,從 JDK 1.7 版開始,還可以是字符串(String)。長整型(long)是不可以的。
&運(yùn)算符是:邏輯與;&&運(yùn)算符是:短路與。
1)&和&&在程序中最終的運(yùn)算結(jié)果是完全一致的,只不過&&存在短路現(xiàn)象。如果是&運(yùn)算符,那么不管左邊的表達(dá)式是true還是false,右邊表達(dá)式是一定會執(zhí)行的。當(dāng)&&運(yùn)算符左邊的表達(dá)式結(jié)果為false的時(shí)候,右邊的表達(dá)式不執(zhí)行,此時(shí)就發(fā)生了短路現(xiàn)象,也就是說&&會更加的智能。這就是他們倆的本質(zhì)區(qū)別。
2)當(dāng)然,&運(yùn)算符還可以使用在二進(jìn)制位運(yùn)算上,例如按位與操作。
char 類型可以存儲一個(gè)中文漢字,因?yàn)镴ava中使用的編碼是Unicode編碼,一個(gè)char 類型占2個(gè)字節(jié)(16 比特),所以放一個(gè)中文是沒問題的。
補(bǔ)充:使用Unicode 意味著字符在JVM內(nèi)部和外部有不同的表現(xiàn)形式,在JVM內(nèi)部都是 Unicode,當(dāng)這個(gè)字符被從JVM內(nèi)部轉(zhuǎn)移到外部時(shí)(例如存入文件系統(tǒng)中),需要進(jìn)行編碼轉(zhuǎn)換。所以 Java 中有字節(jié)流和字符流,以及在字符流和字節(jié)流之間進(jìn)行轉(zhuǎn)換的轉(zhuǎn)換流,如 InputStreamReader和OutputStreamReader,這兩個(gè)類是字節(jié)流和字符流之間的適配器類,承擔(dān)了編碼轉(zhuǎn)換的任務(wù)。
早期的 JDK 中,switch(expr)中,expr 可以是 byte、short、char、int。從 1.5 版開始,Java 中引入了枚舉類型(enum),expr 也可以是枚舉,從 JDK 1.7 版開始,還可以是字符串(String)。長整型(long)是不可以的。
Math.round(11.5)的返回值是12,Math.round(-11.5)的返回值是-11。四舍五入的原理是在參數(shù)上加0.5然后進(jìn)行取整。
前者不正確,后者正確。
對于 short s1 = 1; s1 = s1 + 1;由于 1 是 int 類型,因此 s1+1 運(yùn)算結(jié)果也是 int 型,需要強(qiáng)制轉(zhuǎn)換類型才能賦值給 short 型。
而 short s1 = 1; s1 += 1;可以正確編譯,因?yàn)?s1+= 1;相當(dāng)于 s1 = (short)(s1 + 1);其中有隱含的強(qiáng)制類型轉(zhuǎn)換。
Java中的數(shù)組沒有l(wèi)ength()方法,但是有l(wèi)ength屬性。String有l(wèi)ength()方法。
2 << 3,將2左移3位
public class Test{
????public static void main(String[] args) {
???????Integer f1 = 100, f2 = 100, f3 = 150, f4 = 150; System.out.println(f1 == f2);
???????System.out.println(f3 == f4);
????}
}f1==f2的結(jié)果是 true,而f3==f4 的結(jié)果是false。為什么呢?先來說說裝箱的本質(zhì)。當(dāng)我們給一個(gè)Integer 對象賦一個(gè) int 值的時(shí)候,會調(diào)用 Integer 類的靜態(tài)方法 valueOf,如果看看valueOf的源代碼就知道發(fā)生了什么。如果整型字面量的值在-128 到 127 之間,那么不會 new 新的 Integer 對象,而是直接引用常量池中的Integer對象,所以上面的面試題中f1==f2的結(jié)果是 true,而f3==f4 的結(jié)果是false。
Java 的JDK從 1.5 開始引入了自動裝箱/拆箱機(jī)制。它為每一個(gè)基本數(shù)據(jù)類型都引入了對應(yīng)的包裝類型(wrapper class),int的包裝類就是 Integer,其它基本類型對應(yīng)的包裝類如下:
原始類型: boolean,char,byte,short,int,long,float,double包裝類型:Boolean,Character,Byte,Short,Integer,Long,F(xiàn)loat,Double
方法的返回值是指我們獲取到的某個(gè)方法體中的代碼執(zhí)行后產(chǎn)生的結(jié)果!(前提是該方法可能 產(chǎn)生結(jié)果)。返回值的作用:接收出結(jié)果,使得它可以用于其他的操作!
調(diào)用數(shù)值類型相應(yīng)包裝類中的方法 parse***(String)或 valueOf(String) 即可返回相應(yīng)基本類型或包裝類型數(shù)值;
將數(shù)字與空字符串相加即可獲得其所對應(yīng)的字符串;另外對于基本類型 數(shù)字還可調(diào)用 String 類中的 valueOf(…)方法返回相應(yīng)字符串,而對于包裝類型數(shù)字則可調(diào)用其 toString()方法獲得相應(yīng)字符串;
可用該數(shù)字構(gòu)造一 java.math.BigDecimal 對象,再利用其 round()方法 進(jìn)行四舍五入到保留小數(shù)點(diǎn)后兩位,再將其轉(zhuǎn)換為字符串截取最后兩位。
false,因?yàn)橛行└↑c(diǎn)數(shù)不能完全精確的表示出來。
java中有三種移位運(yùn)算符
<< :左移運(yùn)算符,x << 1,相當(dāng)于x乘以2(不溢出的情況下),低位補(bǔ)0
>> :帶符號右移,x >> 1,相當(dāng)于x除以2,正數(shù)高位補(bǔ)0,負(fù)數(shù)高位補(bǔ)1
>>> :無符號右移,忽略符號位,空位都以0補(bǔ)齊
泛型中類型擦除 Java泛型這個(gè)特性是從JDK 1.5才開始加入的,因此為了兼容之前的版本,Java泛型的實(shí)現(xiàn)采取了“偽泛型”的策略,即Java在語法上支持泛型,但是在編譯階段會進(jìn)行所謂的“類型擦除”(Type Erasure),將所有的泛型表示(尖括號中的內(nèi)容)都替換為具體的類型(其對應(yīng)的原生態(tài)類型),就像完全沒有泛型一樣。
注解是JDK1.5版本開始引入的一個(gè)特性,用于對代碼進(jìn)行說明,可以對包、類、接口、字段、方法參數(shù)、局部變量等進(jìn)行注解。它主要的作用有以下四方面: 生成文檔,通過代碼里標(biāo)識的元數(shù)據(jù)生成javadoc文檔。 編譯檢查,通過代碼里標(biāo)識的元數(shù)據(jù)讓編譯器在編譯期間進(jìn)行檢查驗(yàn)證。 編譯時(shí)動態(tài)處理,編譯時(shí)通過代碼里標(biāo)識的元數(shù)據(jù)動態(tài)處理,例如動態(tài)生成代碼。 運(yùn)行時(shí)動態(tài)處理,運(yùn)行時(shí)通過代碼里標(biāo)識的元數(shù)據(jù)動態(tài)處理,例如使用反射注入實(shí)例。
Java自帶的標(biāo)準(zhǔn)注解,包括@Override、@Deprecated和@SuppressWarnings,分別用于標(biāo)明重寫某個(gè)方法、標(biāo)明某個(gè)類或方法過時(shí)、標(biāo)明要忽略的警告,用這些注解標(biāo)明后編譯器就會進(jìn)行檢查。
元注解:元注解是用于定義注解的注解,包括@Retention、@Target、@Inherited、@Documented @Retention用于標(biāo)明注解被保留的階段 @Target用于標(biāo)明注解使用的范圍 @Inherited用于標(biāo)明注解可繼承 @Documented用于標(biāo)明是否生成javadoc文檔 自定義注解,可以根據(jù)自己的需求定義注解,并可用元注解對自定義注解進(jìn)行注解。
整體上是封裝、繼承、多態(tài)、抽象。
首先面向?qū)ο笫且环N思想。在java中萬事萬物皆對象。類是對相同事物的一種抽象、是不可見的,對象具體的、可見的。由對象到類的過程是抽象的過程,由類到對象的過程是實(shí)例化的過程。面向?qū)ο蟮娜筇卣鞣謩e是封裝、繼承和多態(tài)。
封裝隱藏了類的內(nèi)部實(shí)現(xiàn)機(jī)制,對外界而言它的內(nèi)部細(xì)節(jié)是隱藏的,暴露給外界的只是它的訪問方法。例如在屬性的修飾符上我們往往用的private私有的,這樣其它類要想訪問就通過get和set方法。因此封裝可以程序員按照既定的方式調(diào)用方法,不必關(guān)心方法的內(nèi)部實(shí)現(xiàn),便于使用; 便于修改,增強(qiáng) 代碼的可維護(hù)性。
繼承在本質(zhì)上是特殊~一般的關(guān)系,即常說的is-a關(guān)系。子類繼承父類,表明子類是一種特殊的父類,并且具有父類所不具有的一些屬性或方法。比如從貓類、狗類中可以抽象出一個(gè)動物類,具有和貓、狗、虎類的共同特性(吃、跑、叫等)。通過extends關(guān)鍵字來實(shí)現(xiàn)繼承。Java中的繼承是單繼承,即一個(gè)子類只允許有一個(gè)父類。
Java多態(tài)是指的是首先兩個(gè)類有繼承關(guān)系,其次子類重寫了父類的方法,最后父類引用指向子類對象。如Animal a=new Dog();這行代碼就體現(xiàn)了多態(tài)。
Java中的多態(tài)靠的是父類或接口定義的引用變量可以指向子類或具體實(shí)現(xiàn)類的實(shí)例對象,而程 序調(diào)用的方法在運(yùn)行期才動態(tài)綁定,就是引用變量所指向的具體實(shí)例對象的方法,也就是內(nèi)存 里正在運(yùn)行的那個(gè)對象的方法,而不是引用變量的類型中定義的方法。
名字與類名相同;
沒有返回值,但不能用void聲明構(gòu)造函數(shù);
生成類的對象時(shí)自動執(zhí)行,無需調(diào)用。
構(gòu)造器不能被繼承,因此不能被重寫,但可以被重載。
super可以理解為是指向自己超(父)類對象的一個(gè)指針,而這個(gè)超類指的是離自己最近的一 個(gè)父類。
super也有三種用法:
1.普通的直接引用
與this類似,super相當(dāng)于是指向當(dāng)前對象的父類的引用,這樣就可以用super.xxx來引用父類的成員。
2.子類中的成員變量或方法與父類中的成員變量或方法同名時(shí),用super進(jìn)行區(qū)分
class Person{?
? ? protected String name;?
? ? public Person(String name){?
? ? ? ? this.name = name;?
? ? }?
}?
class StudentextendsPerson{?
? ? private String name;?
? ? publicStudent(String name, String name1){?
? ? ? ? super(name);?
? ? ? ? this.name = name1;?
? ? }?
? ? public void getInfo(){?
? ? ? ? System.out.println(this.name);?
? ? ? ? System.out.println(super.name);?
? ? }?
}?
public class Test{?
? ? public static void main(String[] args){?
? ? ? ? Student s1 = new Student("Father", "Child");?
? ? ? ? s1.getInfo();?
? ? }?
}3.引用父類構(gòu)造函數(shù)
super(參數(shù)):調(diào)用父類中的某一個(gè)構(gòu)造函數(shù)(應(yīng)該為構(gòu)造函數(shù)中的第一條語句)。
this(參數(shù)):調(diào)用本類中另一種形式的構(gòu)造函數(shù)(應(yīng)該為構(gòu)造函數(shù)中的第一條語句)。
super:它引用當(dāng)前對象的直接父類中的成員(用來訪問直接父類中被隱藏的父類中成員
數(shù)據(jù)或函數(shù),基類與派生類中有相同成員定義時(shí)如:super.變量名 super.成員函數(shù)據(jù)名 (實(shí)參)
this:它代表當(dāng)前對象名(在程序中易產(chǎn)生二義性之處,應(yīng)使用this來指明當(dāng)前對象;如果函數(shù)的形參與類中的成員數(shù)據(jù)同名,這時(shí)需用this來指明成員變量名)
super()和this()區(qū)別是
[1]super()在子類中調(diào)用父類的構(gòu)造方法,this()在本類內(nèi)調(diào)用本類的其它構(gòu)造方法。
[2]super()和this()均需放在構(gòu)造方法內(nèi)第一行。盡管可以用this調(diào)用一個(gè)構(gòu)造器,但卻不能調(diào)用兩個(gè)。
[3]this和super不能同時(shí)出現(xiàn)在一個(gè)構(gòu)造函數(shù)里面,因?yàn)閠his必然會調(diào)用其它的構(gòu)造函數(shù),其它的構(gòu)造函數(shù)必然也會有super語句的存在,所以在同一個(gè)構(gòu)造函數(shù)里面有相同的語 句,就失去了語句的意義,編譯器也不會通過。
[4]this()和super()都指的是對象,所以,均不可以在static環(huán)境中使用。包括:static變
量,static方法,static語句塊。從本質(zhì)上講,this是一個(gè)指向本對象的指針, 然而super是一個(gè)Java關(guān)鍵字。
方法的重載和重寫本質(zhì)都是實(shí)現(xiàn)多態(tài)的方式,區(qū)別在于前者實(shí)現(xiàn)的是編譯時(shí)的多態(tài)性,而后者實(shí)現(xiàn)的是運(yùn)行時(shí)的多態(tài)。
方法重載的規(guī)則:
1)方法名一致,
2)參數(shù)列表不同(參數(shù)順序不同或者參數(shù)類型不同或者參數(shù)個(gè)數(shù)不同)。
3)重載與方法的返回值無關(guān),這個(gè)很關(guān)鍵。
方法重寫的規(guī)則:
1)參數(shù)列表和返回值類型必須完全與父類的方法一致
2)構(gòu)造方法不能被重寫,聲明為 final 的方法不能被重寫,聲明為 static 的方法不能被重寫,但是能夠被再次聲明。
3)訪問權(quán)限不能比父類中被重寫的方法的訪問權(quán)限更低。
4)重寫的方法能夠拋出任何檢查異常(編譯時(shí)異常),但是重寫的方法不能拋出比被重寫方法聲明的更廣泛的運(yùn)行時(shí)異常。
1)接口中的所有方法都是抽象的,而抽象類可以有抽象方法,也可以有實(shí)例方法。
2)類需要繼承,接口需要實(shí)現(xiàn)。一個(gè)類可以實(shí)現(xiàn)多個(gè)接口,但只能繼承一個(gè)父類但接口卻可以繼承多接口。
3)接口與實(shí)現(xiàn)它的類不構(gòu)成繼承體系,即接口不是類體系的一部分。因此,不相關(guān)的類也可以實(shí)現(xiàn)相同的接口,而抽象類是屬于類的繼承體系,并且一般位于類體系的頂層。
接口可以繼承接口。抽象類可以實(shí)現(xiàn)(implements)接口,抽象類可繼承具體類,但前提是具體類必須有明確的構(gòu)造函數(shù)。
值傳遞是指在調(diào)用函數(shù)時(shí)將實(shí)際參數(shù)復(fù)制一份到函數(shù)中,這樣的話如果函數(shù)對其傳遞過來的形式參數(shù)進(jìn)行修改,將不會影響到實(shí)際參數(shù)。
引用傳遞是指在調(diào)用函數(shù)時(shí)將對象的地址直接傳遞到函數(shù)中,如果在對形式參數(shù)進(jìn)行修改,將影響到實(shí)際參數(shù)的值。
equals 和== 最大的區(qū)別是一個(gè)是方法一個(gè)是運(yùn)算符。
1)基本類型中,==比較的是數(shù)值是否相等。equals方法是不能用于基本數(shù)據(jù)類型數(shù)據(jù)比較的,因?yàn)榛緮?shù)據(jù)類型壓根就沒有方法。
2)引用類型中,==比較的是對象的地址值是否相等。equals方法比較的是引用類型的變量所指向的對象的地址是否相等。應(yīng)為String這個(gè)類重寫了equals方法,比較的是字符串的內(nèi)容。
hashCode() 的作用是獲取哈希碼,也稱為散列碼;它實(shí)際上是返回一個(gè)int整數(shù)。這個(gè)哈希碼 的作用是確定該對象在哈希表中的索引位置。hashCode() 定義在JDK的Object.java中,這就 意味著Java中的任何類都包含有hashCode()函數(shù)。
在Java中,每個(gè)對象都可以調(diào)用自己的hashCode方法得到自己的哈希值(hashCode),相當(dāng)于對象的指紋信息,通常說世界上沒有完全一樣的指紋,但是在Java中沒有這么絕對,我們依然可以用hashCode值來做一些提前的判斷。
1)如果兩個(gè)對象的hashCode值不一樣,那么他們肯定是不同的兩個(gè)對象;
2)如果兩個(gè)對象的hashCode值一樣,也不代表就是同一個(gè)對象;
3)如果兩個(gè)對象的equals方法相等,那么他們的hashCode值一定相等。
在Java的一些集合類的實(shí)現(xiàn)中,在比較兩個(gè)對象的值是否相等的時(shí)候,會根據(jù)上面的基本原則,先調(diào)用對象的hashCode值來進(jìn)行比較,如果hashCode值不一樣,就可以認(rèn)定這是兩個(gè)不一樣的數(shù)據(jù),如果hashCode值相同,我們會進(jìn)一步調(diào)用equals()方法進(jìn)行內(nèi)容的比較。
equals 方法是用來比較對象大小是否相等的方法,hashcode 方法是用來判斷每個(gè)對象 hash 值的一種方法。如果只重寫 equals 方法而不重寫 hashcode 方法,很可能會造成兩個(gè)不同的對象,它們的 hashcode 也相等,造成沖突。
例如:String str1 = "通話"; String str2 = "重地";
它們兩個(gè)的 hashcode 相等,但是 equals 可不相等。
不對,如果兩個(gè)對象x和y滿足x.equals(y) == true,它們的哈希碼(hash code)應(yīng)當(dāng)相同。
Java對于eqauls方法和hashCode方法是這樣規(guī)定的:
(1)如果兩個(gè)對象相同(equals方法返回true),那么它們的hashCode值一定要相同;
(2)如果兩個(gè)對象的hashCode相同,它們并不一定相同。
當(dāng)然,你未必要按照要求去做,但是如果你違背了上述原則就會發(fā)現(xiàn)在使用容器時(shí),相同的對 象可以出現(xiàn)在Set集合中,同時(shí)增加新元素的效率會大大下降(對于使用哈希存儲的系統(tǒng),如 果哈希碼頻繁的沖突將會造成存取性能急劇下降)。
都不能。
1)抽象方法需要子類重寫,而靜態(tài)的方法是無法被重寫的,因此二者是矛盾的。
2)本地方法是由本地代碼(如 C++ 代碼)實(shí)現(xiàn)的方法,而抽象方法是沒有實(shí)現(xiàn)的,也是矛盾的。
3)synchronized 和方法的實(shí)現(xiàn)細(xì)節(jié)有關(guān),抽象方法不涉及實(shí)現(xiàn)細(xì)節(jié),因此也是相互矛盾的。
修飾類:當(dāng)用final修飾一個(gè)類時(shí),表明這個(gè)類不能被繼承。正如String類是不能被繼承的。final類中的成員變量可以根據(jù)需要設(shè)為final,但是要注意final類中的所有成員方法都會被隱式地指定為final方法。
修飾方法:使用final修飾方法的原因有兩個(gè)。第一個(gè)原因是把方法鎖定,以防任何繼承類修改它的含義;第二個(gè)原因是效率。在早期的Java實(shí)現(xiàn)版本中,會將final方法轉(zhuǎn)為內(nèi)嵌調(diào)用。但是如果方法過于龐大,可能看不到內(nèi)嵌調(diào)用帶來的任何性能提升。在最近的Java版本中,不需要使用final方法進(jìn)行這些優(yōu)化了。因此,只有在想明確禁止該方法在子類中被覆蓋的情況下才將方法設(shè)置為final。(注:一個(gè)類中的private方法會隱式地被指定為final方法)
修飾變量:對于被final修飾的變量,如果是基本數(shù)據(jù)類型的變量,則其數(shù)值一旦在初始化之后便不能更改;如果是引用類型的變量,則在對其初始化之后便不能再讓其指向另一個(gè)對象。雖然不能再指向其他對象,但是它指向的對象的內(nèi)容是可變的。
public class Demo1 {
????public static void main(String[] args) ?{
????????MyClass myClass1 = new MyClass();
????????MyClass myClass2 = new MyClass();
????????System.out.println(myClass1.i);
????????System.out.println(myClass2.i);
????????System.out.println(myClass1.j);
????????System.out.println(myClass2.j); ?
????}
}
class MyClass {
????public final double i = Math.random();
????public static double j = Math.random();
}運(yùn)行結(jié)果:
0.3222977275463088
0.2565532218939688
0.36856868882926397
0.36856868882926397每次打印的兩個(gè)j值都是一樣的,而i的值卻是不同的。從這里就可以知道final和static變量的區(qū)別了。static屬于類級別的不可變,而final是對象級別的不可變。
1)final:用于聲明屬性,方法和類,分別表示屬性不可變,方法不可覆蓋,被其修飾的類不可繼承。
2)finally:異常處理語句結(jié)構(gòu)的一部分,表示總是執(zhí)行。
3)finalize:Object 類的一個(gè)方法,當(dāng)java對象沒有更多的引用指向的時(shí)候,系統(tǒng)會自動的由垃圾回收器來負(fù)責(zé)調(diào)用此方法進(jìn)行回收前的準(zhǔn)備工作和垃圾回收。
靜態(tài)變量: 靜態(tài)變量由于不屬于任何實(shí)例對象,屬于類的,所以在內(nèi)存中只會有一份,在類的 加載過程中,JVM只為靜態(tài)變量分配一次內(nèi)存空間。
實(shí)例變量: 每次創(chuàng)建對象,都會為每個(gè)對象分配成員變量內(nèi)存空間,實(shí)例變量是屬于實(shí)例對象 的,在內(nèi)存中,創(chuàng)建幾次對象,就有幾份成員變量。
靜態(tài)方法和實(shí)例方法的區(qū)別主要體現(xiàn)在兩個(gè)方面:
在外部調(diào)用靜態(tài)方法時(shí),可以使用"類名.方法名"的方式,也可以使用"對象名.方法名"的 方式。而實(shí)例方法只有后面這種方式。也就是說,調(diào)用靜態(tài)方法可以無需創(chuàng)建對象。
靜態(tài)方法在訪問本類的成員時(shí),只允許訪問靜態(tài)成員(即靜態(tài)成員變量和靜態(tài)方法), 而不允許訪問實(shí)例成員變量和實(shí)例方法;實(shí)例方法則無此限制。
class A{
static{
System.out.print("1");
}
public A(){
System.out.print("2");
}
}
class B extends A{
static{
System.out.print("a");
}
public B(){
System.out.print("b");
}
}
public class Hello{
public static void main(String[] ars){
A ab = new B(); //執(zhí)行到此處,結(jié)果: 1a2b
ab = new B(); //執(zhí)行到此處,結(jié)果: 1a2b2b
}
}?| 修飾符 | 當(dāng)前類 | 同包 | 子類 | 其它包 |
|---|---|---|---|---|
| public | 是 | 是 | 是 | 是 |
| protected | 是 | 是 | 是 | 否 |
| 默認(rèn)(缺省) | 是 | 是 | 否 | 否 |
| private | 是 | 否 | 否 | 否 |
類的成員不寫訪問修飾時(shí)默認(rèn)為default。默認(rèn)對于同一個(gè)包中的其他類相當(dāng)于公開 (public),對于不是同一個(gè)包中的其他類相當(dāng)于私有(private)。受保護(hù)(protected)對 子類相當(dāng)于公開,對不是同一包中的沒有父子關(guān)系的類相當(dāng)于私有。Java中,外部類的修飾符 只能是public或默認(rèn),類的成員(包括內(nèi)部類)的修飾符可以是以上四種。
goto 是Java中的保留字,在目前版本的Java中沒有使用。(根據(jù)James Gosling(Java之 父)編寫的《The Java Programming Language》一書的附錄中給出了一個(gè)Java關(guān)鍵字列 表,其中有g(shù)oto和const,但是這兩個(gè)是目前無法使用的關(guān)鍵字,因此有些地方將其稱之為保 留字,其實(shí)保留字這個(gè)詞應(yīng)該有更廣泛的意義,因?yàn)槭煜語言的程序員都知道,在系統(tǒng)類庫 中使用過的有特殊意義的單詞或單詞的組合都被視為保留字)
由于 Java 不支持多繼承,而有可能某個(gè)類或?qū)ο笠褂梅謩e在幾個(gè)類或?qū)ο罄锩娴姆椒ɑ驅(qū)傩裕F(xiàn)有的單繼承機(jī)制就不能滿足要求。與繼承相比,接口有更高的靈活性,因?yàn)榻涌谥袥]有任何實(shí)現(xiàn)代碼。當(dāng)一個(gè)類實(shí)現(xiàn)了接口以后,該類要實(shí)現(xiàn)接口里面所有的方法和屬性,并且接口里面的屬性在默認(rèn)狀態(tài)下面都是public static,所有方法默認(rèn)情況下是 public.一個(gè)類可以實(shí)現(xiàn)多個(gè)接口。
不是。Java 中的基本數(shù)據(jù)類型只有 8 個(gè):byte、short、int、long、float、double、char、boolean;除了基本類型(primitive type)外,剩下的都是引用類型(reference type)
1)String是只讀的字符串,因此String引用的字符串內(nèi)容是不能被改變的。
String str = "abc";
str = "bcd";
如上,第一行str 僅僅是一個(gè)引用對象,它指向一個(gè)字符串對象“abc”。第二行代碼的含義是讓 str 重新指向了一個(gè)新的字符串“bcd”對象,而“abc”對象并沒有任何改變
2)StringBuffer/StringBuilder 表示的字符串對象可以直接進(jìn)行修改。
3)StringBuilder 是 Java5 中引入的,它和 StringBuffer 的方法完全相同,區(qū)別在于它是在單線程環(huán)境下使用的,因?yàn)樗乃蟹椒ǘ紱]有被 synchronized 修飾,因此它的效率理論上也比 StringBuffer 要高。
不一樣,因?yàn)閮?nèi)存的分配方式不一樣。String str = "i"的方式JVM會將其分配到常量池中,而 String str = new String("i")JVM會將其分配到堆內(nèi)存中。
String 類是final類,不可以被繼承。
補(bǔ)充:繼承String本身就是一個(gè)錯(cuò)誤的行為,對String類型最好的重用方式是關(guān)聯(lián)關(guān)系 (Has-A)和依賴關(guān)系(Use-A)而不是繼承關(guān)系(Is-A)。
兩個(gè)對象,一個(gè)是靜態(tài)存儲區(qū)的"xyz",一個(gè)是用 new 創(chuàng)建在堆上的對象。
indexof();返回指定字符的的索引。
charAt();返回指定索引處的字符。
replace();字符串替換。
trim();去除字符串兩端空格。
splt();字符串分割,返回分割后的字符串?dāng)?shù)組。
getBytes();返回字符串byte類型數(shù)組。
length();返回字符串長度。
toLowerCase();將字符串轉(zhuǎn)換為小寫字母。
toUpperCase();將字符串轉(zhuǎn)換為大寫字母。
substring();字符串截取。
equals();比較字符串是否相等。
數(shù)組沒有 length()方法,有 length 的屬性。String 有 length()方法。JavaScript 中,獲得字符串的長度是通過 length 屬性得到的,這一點(diǎn)容易和 Java混淆
String s1 = "你好"; String s2 = newString(s1.getBytes("GB2312"), "ISO-8859-1");
首先會判斷要比較的兩個(gè)字符串它們的引用是否相等。如果引用相等的話,直接返回 true ,不相等的話繼續(xù)下面的判斷,然后再判斷被比較的對象是否是 String 的實(shí)例,如果不是的話直接返回 false,如果是的話,再比較兩個(gè)字符串的長度是否相等,如果長度不想等的話也就沒有比較的必要了;長度如果相同,會比較字符串中的每個(gè) 字符 是否相等,一旦有一個(gè)字符不相等,就會直接返回 false。
用遞歸實(shí)現(xiàn)字符串反轉(zhuǎn),代碼如下所示:
public static String reverse(String originStr) {
? if(originStr == null || originStr.length() <= 1)
? return originStr;
? return reverse(originStr.substring(1)) + originStr.charAt(0);
}string.substring(from):相當(dāng)于從from位置截取到原字符串末尾
charAt() 方法用于返回指定索引處的字符。索引范圍為從 0 到 length() - 1。
public String[] split(String str, int chars){
int n = (str.length()+ chars - 1)/chars;
String ret[] = new String[n];
for(int i=0; i<n; i++){
if(i < n-1){
ret[i] = str.substring(i*chars , (i+1)*chars);
}else{
ret[i] = str.substring(i*chars);
}
}
return ret;
} 代碼如下:
public String subString(String str, int subBytes) {
int bytes = 0; // 用來存儲字符串的總字節(jié)數(shù)
for (int i = 0; i < str.length(); i++) {
if (bytes == subBytes) {
return str.substring(0, i);
}
char c = str.charAt(i);
if (c < 256) {
bytes += 1; // 英文字符的字節(jié)數(shù)看作 1
} else {
bytes += 2; // 中文字符的字節(jié)數(shù)看作 2
if(bytes - subBytes == 1){
return str.substring(0, i);
}
}
}
return str;
}package test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
import java.util.Random;
public class RandomSort {
public static void printRandomBySort() {
Random random = new Random(); // 創(chuàng)建隨機(jī)數(shù)生成器
List list = new ArrayList(); // 生成 10 個(gè)隨機(jī)數(shù),并放在集合 list 中
for (int i = 0; i < 10; i++) {
list.add(random.nextInt(1000));
}
Collections.sort(list); // 對集合中的元素進(jìn)行排序
Iterator it = list.iterator();
int count = 0;
while (it.hasNext()) { // 順序輸出排序后集合中的元素
System.out.println(++count + ": " + it.next());
}
}
public static void main(String[] args) {
printRandomBySort();
}
} public int countWords(String file, String find) throws Exception {
int count = 0;
Reader in = new FileReader(file);
int c;
while ((c = in.read()) != -1) {
while (c == find.charAt(0)) {
for (int i = 1; i < find.length(); i++) {
c = in.read();
if (c != find.charAt(i))
break;
if (i == find.length() - 1)
count++;
}
}
}
return count;
}Object類提供了如下幾個(gè)常用方法:
Class<?> getClass():返回該對象的運(yùn)行時(shí)類。
boolean equals(Object obj):判斷指定對象與該對象是否相等。
int hashCode():返回該對象的hashCode值。在默認(rèn)情況下,Object類的hashCode()方法根據(jù)該對象的地址來計(jì)算。但很多類都重寫了Object類的hashCode()方法,不再根據(jù)地址來計(jì)算其hashCode()方法值。
String toString():返回該對象的字符串表示,當(dāng)程序使用System.out.println()方法輸出一個(gè)對象,或者把某個(gè)對象和字符串進(jìn)行連接運(yùn)算時(shí),系統(tǒng)會自動調(diào)用該對象的toString()方法返回該對象的字符串表示。Object類的toString()方法返回 運(yùn)行時(shí)類名@十六進(jìn)制hashCode值 格式的字符串,但很多類都重寫了Object類的toString()方法,用于返回可以表述該對象信息的字符串。
另外,Object類還提供了wait()、notify()、notifyAll()這幾個(gè)方法,通過這幾個(gè)方法可以控制線程的暫停和運(yùn)行。Object類還提供了一個(gè)clone()方法,該方法用于幫助其他對象來實(shí)現(xiàn)“自我克隆”,所謂“自我克隆”就是得到一個(gè)當(dāng)前對象的副本,而且二者之間完全隔離。由于該方法使用了protected修飾,因此它只能被子類重寫或調(diào)用。
Object類提供的equals()方法默認(rèn)是用==來進(jìn)行比較的,也就是說只有兩個(gè)對象是同一個(gè)對象時(shí),才能返回相等的結(jié)果。而實(shí)際的業(yè)務(wù)中,我們通常的需求是,若兩個(gè)不同的對象它們的內(nèi)容是相同的,就認(rèn)為它們相等。鑒于這種情況,Object類中equals()方法的默認(rèn)實(shí)現(xiàn)是沒有實(shí)用價(jià)值的,所以通常都要重寫。
垃圾回收器回收對象前,會調(diào)用此方法,可以在此方法中做釋放資源等清理操作
這兩個(gè)方法用來提示 JVM 要進(jìn)行垃圾回收。但是,立即開始還是延遲進(jìn)行垃圾回收是取決于 JVM 的。
利用 java.text.DataFormat 的子類(如 SimpleDateFormat 類)中的 format(Date)方法可將日期格式化。
參考如下源代碼:
public class YesterdayCurrent{
public static void main(String[] args){
Calendar cal = Calendar.getInstance();
cal.add(Calendar.DATE, -1);
System.out.println(cal.getTime());
}
}使用Math.random()可以生成0.1到1.0范圍內(nèi)的隨機(jī)數(shù)字,然后通過數(shù)學(xué)方法實(shí)現(xiàn)生成 符合要求的隨機(jī)數(shù)。
在Java中,可以將一個(gè)類的定義放在另外一個(gè)類的定義內(nèi)部,這就是 內(nèi)部類 。內(nèi)部類本身就 是類的一個(gè)屬性,與其他屬性定義方式一致。
內(nèi)部類可以分為四種: 成員內(nèi)部類、局部內(nèi)部類、匿名內(nèi)部類和靜態(tài)內(nèi)部類 。
一個(gè)內(nèi)部類對象可以訪問創(chuàng)建它的外部類對象的成員,包括私有成員。
可以繼承其他類或?qū)崿F(xiàn)其他接口,在 Swing 編程中常用此方式來實(shí)現(xiàn)事件監(jiān)聽和回調(diào)
Throwable 是 Java 語言中所有錯(cuò)誤與異常的超類。
Error 類及其子類:程序中無法處理的錯(cuò)誤,表示運(yùn)行應(yīng)用程序中出現(xiàn)了嚴(yán)重的錯(cuò)誤。
Exception 程序本身可以捕獲并且可以處理的異常。Exception 這種異常又分為兩類:運(yùn)行時(shí)異常和編譯時(shí)異常。
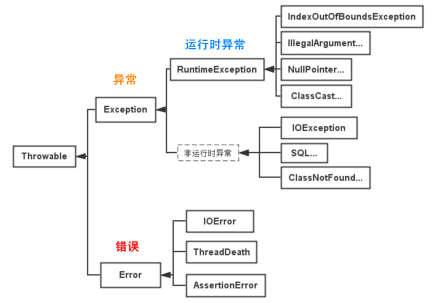
運(yùn)行時(shí)異常 都是RuntimeException類及其子類異常,如NullPointerException(空指針異常)、IndexOutOfBoundsException(下標(biāo)越界異常)等,這些異常是不檢查異常,程序中可以選擇捕獲處理,也可以不處理。這些異常一般是由程序邏輯錯(cuò)誤引起的,程序應(yīng)該從邏輯角度盡可能避免這類異常的發(fā)生。 運(yùn)行時(shí)異常的特點(diǎn)是Java編譯器不會檢查它,也就是說,當(dāng)程序中可能出現(xiàn)這類異常,即使沒有用try-catch語句捕獲它,也沒有用throws子句聲明拋出它,也會編譯通過。
非運(yùn)行時(shí)異常 (編譯異常)是RuntimeException以外的異常,類型上都屬于Exception類及其子類。從程序語法角度講是必須進(jìn)行處理的異常,如果不處理,程序就不能編譯通過。如IOException、SQLException等以及用戶自定義的Exception異常,一般情況下不自定義檢查異常。
異常需要處理的時(shí)機(jī)分為編譯時(shí)異常(也叫受控異常)也叫 CheckedException 和運(yùn)行時(shí)異常(也叫非受控異常)也叫 UnCheckedException。Java認(rèn)為Checked異常都是可以被處理的異常,所以Java程序必須顯式處理Checked異常。如果程序沒有處理Checked 異常,該程序在編譯時(shí)就會發(fā)生錯(cuò)誤無法編譯。這體現(xiàn)了Java 的設(shè)計(jì)哲學(xué):沒有完善錯(cuò)誤處理的代碼根本沒有機(jī)會被執(zhí)行。
對Checked異常處理方法有兩種:
● 第一種:當(dāng)前方法知道如何處理該異常,則用try...catch塊來處理該異常。
● 第二種:當(dāng)前方法不知道如何處理,則在定義該方法時(shí)聲明拋出該異常。
運(yùn)行時(shí)異常只有當(dāng)代碼在運(yùn)行時(shí)才發(fā)行的異常,編譯的時(shí)候不需要try…catch。Runtime如除數(shù)是0和數(shù)組下標(biāo)越界等,其產(chǎn)生頻繁,處理麻煩,若顯示申明或者捕獲將會對程序的可讀性和運(yùn)行效率影響很大。所以由系統(tǒng)自動檢測并將它們交給缺省的異常處理程序。當(dāng)然如果你有處理要求也可以顯示捕獲它們。
Java 的異常處理是通過 5 個(gè)關(guān)鍵詞來實(shí)現(xiàn)的:try、catch、throw、throws 和 finally。
一般情況下是用 try 來執(zhí)行一段程序,如果出現(xiàn)異常,系統(tǒng)會拋出(throw)一個(gè)異常,這時(shí)候你可以通過它的類型來捕捉(catch)它,或最后(finally)由缺省處理器來處理;try 用來指定一塊預(yù)防所有“異常”的程序;catch 子句緊跟在 try 塊后面,用來指定你想要捕捉的“異常”的類型;throw 語句用來明確地拋出一個(gè)“異常”;throws 用來標(biāo)明一個(gè)成員函數(shù)可能拋出的各種“異常”;finally 為確保一段代碼不管發(fā)生什么“異常”都被執(zhí)行一段代碼;可以在一個(gè)成員函數(shù)調(diào)用的外面寫一個(gè) try 語句,在這個(gè)成員函數(shù)內(nèi)部寫另一個(gè) try 語句保護(hù)其他代碼。每當(dāng)遇到一個(gè) try 語句,“異常”的框架就放到棧上面,直到所有的try 語句都完成。如果下一級的 try 語句沒有對某種"異常"進(jìn)行處理,棧就會展開,直到遇到有處理這種"異常"的 try 語句。
會執(zhí)行,在方法返回調(diào)用者前執(zhí)行。Java 允許在 finally 中改變返回值的做法是不好的,因?yàn)槿绻嬖?finally 代碼塊,try 中的 return 語句不會立馬返回調(diào)用者,而是記錄下返回值待 finally 代碼塊執(zhí)行完畢之后再向調(diào)用者返回其值,然后如果在 finally 中修改了返回值,這會對程序造成很大的困擾,C#中就從語法上規(guī)定不能做這樣的事。
Error 表示系統(tǒng)級的錯(cuò)誤和程序不必處理的異常,是恢復(fù)不是不可能但很困難的情況下的一種嚴(yán)重問題;比如內(nèi)存溢出,不可能指望程序能處理這樣的情況;Exception 表示需要捕捉或者需要程序進(jìn)行處理的異常,是一種設(shè)計(jì)或?qū)崿F(xiàn)問題;也就是說,它表示如果程序運(yùn)行正常,從不會發(fā)生的情況。
public int getNum() {
try {
int a = 1 / 0;
return 1;
} catch (Exception e) {
return 2;
} finally {
return 3;
}
}分析:代碼走到第3行的時(shí)候遇到了一個(gè)MathException,這時(shí)第4行的代碼就不會執(zhí)行了,代碼直接跳轉(zhuǎn)到catch語句中,走到第 6 行的時(shí)候,異常機(jī)制有一個(gè)原則:如果在catch中遇到了return或者異常等能使該函數(shù)終止的話那么有finally就必須先執(zhí)行完finally代碼塊里面的代碼然后再返回值。因此代碼又跳到第8行,可惜第8行是一個(gè)return語句,那么這個(gè)時(shí)候方法就結(jié)束了,因此第6行的返回結(jié)果就無法被真正返回。因此上面返回值是3。
有如下代碼片斷:
try{
throw new ExampleB(“b”);
}catch(ExampleA e){
System.out.printfln(“ExampleA”);
}catch(Exception e){
System.out.printfln(“Exception”);
}輸出的內(nèi)容應(yīng)該是:ExampleA
●java.lang.NullPointerException 空指針異常;出現(xiàn)原因:調(diào)用了未經(jīng)初始化的對象或者是不存在的對象。
● java.lang.IndexOutOfBoundsException 數(shù)組角標(biāo)越界異常,常見于操作數(shù)組對象時(shí)發(fā)生。
● java.lang.ClassNotFoundException 指定的類找不到;出現(xiàn)原因:類的名稱和路徑加載錯(cuò)誤;通常都是程序試圖通過字符串來加載某個(gè)類時(shí)可能引發(fā)異常。
● java.lang.ClassCastException 數(shù)據(jù)類型轉(zhuǎn)換異常。
● java.lang.SQLException SQL異常,常見于操作數(shù)據(jù)庫時(shí)的 SQL 語句錯(cuò)誤。
● throw:
throw 語句用在方法體內(nèi),表示拋出異常,由方法體內(nèi)的語句處理。
throw是具體向外拋出異常的動作,所以它拋出的是一個(gè)異常實(shí)例,執(zhí)行throw一定是拋出了某種異常。
● throws:
throws語句是用在方法聲明后面,表示如果拋出異常,由該方法的調(diào)用者來進(jìn)行異常的處理。
throws主要是聲明這個(gè)方法會拋出某種類型的異常,讓它的使用者要知道需要捕獲的異常的類型。
如果你的資源實(shí)現(xiàn)了 AutoCloseable 接口,你可以使用這個(gè)語法。大多數(shù)的 Java 標(biāo)準(zhǔn)資源都繼承了這個(gè)接口。當(dāng)你在 try 子句中打開資源,資源會在 try 代碼塊執(zhí)行后或異常處理后自動關(guān)閉。
public void automaticallyCloseResource() {
File file = new File("./tmp.txt");
try (FileInputStream inputStream = new FileInputStream(file);) {
// use the inputStream to read a file
} catch (FileNotFoundException e) {
log.error(e);
} catch (IOException e) {
log.error(e);
}
}public static void simpleTryCatch() {
try {
testNPE();
} catch (Exception e) {
e.printStackTrace();
}
}使用javap來分析這段代碼(需要先使用javac編譯)。
//javap -c Main
public static void simpleTryCatch();
Code:
0: invokestatic #3 // Method testNPE:()V
3: goto 11
6: astore_0
7: aload_0
8: invokevirtual #5 // Method java/lang/Exception.printStackTrace:()V
11: return
Exception table:
from to target type
0 3 6 Class java/lang/Exception異常表中包含了一個(gè)或多個(gè)異常處理者(Exception Handler)的信息,這些信息包含如下
1)from 可能發(fā)生異常的起始點(diǎn)
2)to可能發(fā)生異常的結(jié)束點(diǎn)
3)target上述from和to之前發(fā)生異常后的異常處理者的位置
4)type異常處理者處理的異常的類信息
IO流就是以流的方式進(jìn)行輸入輸出。主要用來處理設(shè)備之間的傳輸,文件的上傳,下載和復(fù)制。
流分輸入和輸出,輸入流從文件中讀取數(shù)據(jù)存儲到進(jìn)程中,輸出流從進(jìn)程中讀取數(shù)據(jù)然后寫入到目標(biāo)文件。
按照流的方向:輸入流(inputStream)和輸出流(outputStream)
按照實(shí)現(xiàn)功能分:節(jié)點(diǎn)流(可以從或向一個(gè)特定的地方(節(jié)點(diǎn))讀寫數(shù)據(jù)。如 FileReader)和處理流(是對一個(gè)已存在的流的連接和封裝,通過所封裝的流的功能調(diào)用實(shí)現(xiàn)數(shù)據(jù)讀寫。如 BufferedReader。處理流的構(gòu)造方法總是要帶一個(gè)其他的流對象做參數(shù)。一個(gè)流對象經(jīng)過其他流的多次包裝,稱為流的鏈接。)
按照處理數(shù)據(jù)的單位: 字節(jié)流和字符流。字節(jié)流繼承于 InputStream 和 OutputStream, 字符流繼承于Reader 和 Writer 。
1)字節(jié)流讀取的時(shí)候,讀到一個(gè)字節(jié)就返回一個(gè)字節(jié);字符流讀取的時(shí)候會讀到一個(gè)或多個(gè)字節(jié)(這個(gè)要根據(jù)字符流中編碼設(shè)置,一般中文對應(yīng)的字節(jié)數(shù)是兩個(gè),在UTF-8碼表中是3個(gè)字節(jié))
2)字節(jié)流可以處理所有類型數(shù)據(jù),如:圖片,MP3,AVI視頻文件,而字符流只能處理字符數(shù)據(jù)。只要是處理純文本數(shù)據(jù),就要優(yōu)先考慮使用字符流,除此之外都用字節(jié)流。
3)字節(jié)流在操作時(shí)本身不會用到緩沖區(qū)(內(nèi)存),是文件本身直接操作的,而字符流在操作時(shí)使用了緩沖區(qū),通過緩沖區(qū)再操作文件。
案例1:在寫操作的過程中,沒有關(guān)閉字節(jié)流操作,但是文件中也依然存在了輸出的內(nèi)容代碼如下:
public static void main(String[] args) throws Exception {
// 第1步:使用File類找到一個(gè)文件
File f = new File("d:" + File.separator + "test.txt"); // 聲明File 對象
// 第2步:通過子類實(shí)例化父類對象
OutputStream out = new FileOutputStream(f);
// 第3步:進(jìn)行寫操作
String str = "Hello World!!!"; // 準(zhǔn)備一個(gè)字符串
byte b[] = str.getBytes(); // 字符串轉(zhuǎn)byte數(shù)組
out.write(b); // 將內(nèi)容輸出
// 第4步:關(guān)閉輸出流
// out.close();
} 案例2:在寫操作的過程中,沒有關(guān)閉字符流操作,發(fā)現(xiàn)文件中沒有任何內(nèi)容輸出。代碼如下:
public static void main(String[] args) throws Exception {
// 第1步:使用File類找到一個(gè)文件
File f = new File("d:" + File.separator + "test.txt");// 聲明File 對象
// 第2步:通過子類實(shí)例化父類對象
Writer out = new FileWriter(f);
// 第3步:進(jìn)行寫操作
String str = "Hello World!!!"; // 準(zhǔn)備一個(gè)字符串
out.write(str); // 將內(nèi)容輸出
out.flush();
// 第4步:關(guān)閉輸出流
// out.close();
} 這是因?yàn)樽址鞑僮鲿r(shí)使用了緩沖區(qū),而在關(guān)閉字符流時(shí)會強(qiáng)制性地將緩沖區(qū)中的內(nèi)容進(jìn)行輸出,但是如果程序沒有關(guān)閉,則緩沖區(qū)中的內(nèi)容是無法輸出的。當(dāng)然如果在不關(guān)閉字符流的情況下也可以使用Writer類中的flush()強(qiáng)制性的清空緩存,從而將字符流的內(nèi)容全部輸出。
解題思路:把字節(jié)流轉(zhuǎn)成字符流就要用到適配器模式,需要用到OutputStreamWriter。它繼承了Writer接口,但要?jiǎng)?chuàng)建它必須在構(gòu)造函數(shù)中傳入一個(gè)OutputStream的實(shí)例,OutputStreamWriter的作用也就是將OutputStream適配到Writer。它實(shí)現(xiàn)了Reader接口,并且持有了InputStream的引用。利用轉(zhuǎn)換流OutputStreamWriter.創(chuàng)建一個(gè)字節(jié)流對象,將其作為參數(shù)傳入轉(zhuǎn)換流OutputStreamWriter中得到字符流對象.
序列化是指把對象轉(zhuǎn)換為字節(jié)序列的過程,序列化后的字節(jié)流保存了對象的狀態(tài)以及相關(guān)的描述信息,從而方便在網(wǎng)絡(luò)上傳輸或者保存在本地文件中,達(dá)到對象狀態(tài)的保存與重建的目的。
反序列化:客戶端從文件中或網(wǎng)絡(luò)上獲得序列化后的對象字節(jié)流后,根據(jù)字節(jié)流中所保存的對象狀態(tài)及描述信息,通過反序列化重建對象。
序列化的優(yōu)勢:一是實(shí)現(xiàn)了數(shù)據(jù)的持久化,通過序列化可以把數(shù)據(jù)永久地保存到硬盤上(通常存放在文件里),二是,利用序列化實(shí)現(xiàn)遠(yuǎn)程通信,即在網(wǎng)絡(luò)上傳送對象的字節(jié)序列。三是通過序列化在進(jìn)程間傳遞對象;
(1)java.io.ObjectOutputStream:表示對象輸出流;它的writeObject(Object obj)方法可以對參數(shù)指定的obj對象進(jìn)行序列化,把得到的字節(jié)序列寫到一個(gè)目標(biāo)輸出流中;
(2)java.io.ObjectInputStream:表示對象輸入流;它的readObject()方法源輸入流中讀取字節(jié)序列,再把它們反序列化成為一個(gè)對象,并將其返回;
注意:只有實(shí)現(xiàn)了Serializable或Externalizable接口的類的對象才能被序列化,否則拋出異常!
序列化和反序列化的示例
public class SerialDemo {
public static void main(String[] args) throws IOException, ClassNotFoundException {
//序列化
FileOutputStream fos = new FileOutputStream("object.out");
ObjectOutputStream oos = new ObjectOutputStream(fos);
User user1 = new User("xuliugen", "123456", "male");
oos.writeObject(user1);
oos.flush();
oos.close();
//反序列化
FileInputStream fis = new FileInputStream("object.out");
ObjectInputStream ois = new ObjectInputStream(fis);
User user2 = (User) ois.readObject();
System.out.println(user2.getUserName()+ " " +
user2.getPassword() + " " + user2.getSex());
//反序列化的輸出結(jié)果為:xuliugen 123456 male
}
}
public class User implements Serializable {
private String userName;
private String password;
private String sex;
//全參構(gòu)造方法、get和set方法省略
}1. PrintStream 類的輸出功能非常強(qiáng)大,通常如果需要輸出文本內(nèi)容,都應(yīng)該將輸出流包裝成PrintStream 后進(jìn)行輸出。它還提供其他兩項(xiàng)功能。與其他輸出流不同,PrintStream 永遠(yuǎn)不會拋出 IOException;而是,異常情況僅設(shè)置可通過 checkError 方法測試的內(nèi)部標(biāo)志。另外,為了自動刷新,可以創(chuàng)建一個(gè) PrintStream
2.BufferedWriter:將文本寫入字符輸出流,緩沖各個(gè)字符從而提供單個(gè)字符,數(shù)組和字符串的高效寫入。通過 write()方法可以將獲取到的字符輸出,然后通過 newLine()進(jìn)行換行操作。BufferedWriter 中的字符流必須通過調(diào)用 flush 方法才能將其刷出去。并且 BufferedWriter 只能對字符流進(jìn)行操作。如果要對字節(jié)流操作,則使用 BufferedInputStream
3.PrintWriter 的 println 方法自動添加換行,不會拋異常,若關(guān)心異常,需要調(diào)用 checkError方法看是否有異常發(fā)生,PrintWriter 構(gòu)造方法可指定參數(shù),實(shí)現(xiàn)自動刷新緩存(autoflush)。
因?yàn)槊鞔_說了是對字節(jié)流的讀取,所以肯定是InputStream或者他的子類,又因?yàn)橐罅孔x取,肯定要考慮到高效的問題,自然想到緩沖流BufferedInputStream。
原因:BufferedInputStream是InputStream的緩沖流,使用它可以防止每次讀取數(shù)據(jù)時(shí)進(jìn)行實(shí)際的寫操作,代表著使用緩沖區(qū)。不帶緩沖的操作,每讀一個(gè)字節(jié)就要寫入一個(gè)字節(jié),由于涉及磁盤的IO操作相比內(nèi)存的操作要慢很多,所以不帶緩沖的流效率很低。帶緩沖的流,可以一次讀很多字節(jié),但不向磁盤中寫入,只是先放到內(nèi)存里。等湊夠了緩沖區(qū)大小的時(shí)候一次性寫入磁盤,這種方式可以減少磁盤操作次數(shù),速度就會提高很多!并且也可以減少對磁盤的損傷。
集合就是一個(gè)放數(shù)據(jù)的容器,準(zhǔn)確的說是放數(shù)據(jù)對象引用的容器;集合類存放的都是對象的引用,而不是對象的本身;集合類型主要有3種:set(集)、list(列表)和map(映射)。
Java1.5引入了泛型,所有的集合接口和實(shí)現(xiàn)都大量地使用它。泛型允許我們?yōu)榧咸峁┮粋€(gè)可以容納的對象類型,因此,如果你添加其它類型的任何元素,它會在編譯時(shí)報(bào)錯(cuò)。這避免了在運(yùn)行時(shí)出現(xiàn)ClassCastException,因?yàn)槟銓诰幾g時(shí)得到報(bào)錯(cuò)信息。泛型也使得代碼整潔,我們不需要使用顯式轉(zhuǎn)換和instanceOf操作符。它也給運(yùn)行時(shí)帶來好處,因?yàn)椴粫a(chǎn)生類型檢查的字節(jié)碼指令。
Iterator接口提供遍歷任何Collection的接口。我們可以從一個(gè)Collection中使用迭代器方法來獲取迭代器實(shí)例。迭代器取代了Java集合框架中的Enumeration。迭代器允許調(diào)用者在迭代過程中移除元素。
數(shù)組是固定長度的;集合可變長度的。
數(shù)組可以存儲基本數(shù)據(jù)類型,也可以存儲引用數(shù)據(jù)類型;集合只能存儲引用數(shù)據(jù)類型。
數(shù)組存儲的元素必須是同一個(gè)數(shù)據(jù)類型;集合存儲的對象可以是不同數(shù)據(jù)類型。
Map接口和Collection接口是所有集合框架的父接口:
Collection接口的子接口包括:Set接口和List接口
Map接口的實(shí)現(xiàn)類主要有:HashMap、TreeMap、Hashtable、ConcurrentHashMap以及Properties等
Set接口的實(shí)現(xiàn)類主要有:HashSet、TreeSet、LinkedHashSet等
List接口的實(shí)現(xiàn)類主要有:ArrayList、LinkedList、Stack以及Vector等
java.util.Collection 是一個(gè)集合接口(集合類的一個(gè)頂級接口)。它提供了對集合對象進(jìn)行基本操作的通用接口方法。Collection接口在Java 類庫中有很多具體的實(shí)現(xiàn)。Collection接口的意義是為各種具體的集合提供了最大化的統(tǒng)一操作方式,其直接繼承接口有List與Set。
Collections則是集合類的一個(gè)工具類/幫助類,其中提供了一系列靜態(tài)方法,用于對集合中元素進(jìn)行排序、搜索以及線程安全等各種操作。
Set 接口實(shí)例存儲的是無序的,不重復(fù)的數(shù)據(jù)。List 接口實(shí)例存儲的是有序的,可以重復(fù)的元素。都可以存儲null值,但是set不能重復(fù)所以最多只能有一個(gè)空元素。
Set檢索效率低下,刪除和插入效率高,插入和刪除不會引起元素位置改變 <實(shí)現(xiàn)類有HashSet,TreeSet>。
List和數(shù)組類似,可以動態(tài)增長,根據(jù)實(shí)際存儲的數(shù)據(jù)的長度自動增長List的長度。查找元素效率高,插入刪除效率低,因?yàn)闀鹌渌匚恢酶淖?<實(shí)現(xiàn)類有ArrayList,LinkedList,Vector> 。
1)Arraylist 底層使用的是Object數(shù)組;LinkedList 底層使用的是雙向循環(huán)鏈表數(shù)據(jù)結(jié)構(gòu);
2)ArrayList 采用數(shù)組存儲,所以插入和刪除元素的時(shí)間復(fù)雜度受元素位置的影響。插入末尾還好,如果是中間,則(add(int index, E element))接近O(n);LinkedList 采用鏈表存儲,所以插入,刪除元素時(shí)間復(fù)雜度不受元素位置的影響,都是近似 O(1)而數(shù)組為近似 O(n)。對于隨機(jī)訪問get和set,ArrayList優(yōu)于LinkedList,因?yàn)長inkedList要移動指針。
3)LinkedList 不支持高效的隨機(jī)元素訪問,而ArrayList 實(shí)現(xiàn)了RandmoAccess 接口,所以有隨機(jī)訪問功能。快速隨機(jī)訪問就是通過元素的序號快速獲取元素對象(對應(yīng)于get(int index)方法)。所以ArrayList隨機(jī)訪問快,插入慢;LinkedList隨機(jī)訪問慢,插入快。
4)ArrayList的空 間浪費(fèi)主要體現(xiàn)在在list列表的結(jié)尾會預(yù)留一定的容量空間,而LinkedList的空間花費(fèi)則體現(xiàn)在它的每一個(gè)元素都需要消耗比ArrayList更多的空間(因?yàn)橐娣胖苯雍罄^和直接前驅(qū)以及數(shù)據(jù))。
ArrayList和Vector在很多時(shí)候都很類似。
(1)兩者都是基于索引的,內(nèi)部由一個(gè)數(shù)組支持。
(2)兩者維護(hù)插入的順序,我們可以根據(jù)插入順序來獲取元素。
(3)ArrayList和Vector的迭代器實(shí)現(xiàn)都是fail-fast的。
(4)ArrayList和Vector兩者允許null值,也可以使用索引值對元素進(jìn)行隨機(jī)訪問。
以下是ArrayList和Vector的不同點(diǎn)。
(1)Vector是同步的,而ArrayList不是。然而,如果你尋求在迭代的時(shí)候?qū)α斜磉M(jìn)行改變,你應(yīng)該使用CopyOnWriteArrayList。
(2)ArrayList比Vector快,它因?yàn)橛型剑粫^載。
(3)ArrayList更加通用,因?yàn)槲覀兛梢允褂肅ollections工具類輕易地獲取同步列表和只讀列表。
List<String> strList = new ArrayList<>();
//使用for-each循環(huán)
for(String obj : strList){
System.out.println(obj);
}
//using iterator
Iterator<String> it = strList.iterator();
while(it.hasNext()){
String obj = it.next();
System.out.println(obj);
}當(dāng)把對象加入到HashSet中時(shí),HashSet會先計(jì)算對象的hashCode值來判斷對象加入的下標(biāo)位置,同時(shí)也會與其他的對象的hashCode進(jìn)行比較,如果沒有相同的,就直接插入數(shù)據(jù);如果有相同的,就進(jìn)一步使用equals來進(jìn)行比較對象是否相同,如果相同,就不會加入成功。
1.使用foreach循環(huán)遍歷
Map<String, String> hashMap = new HashMap<String,String>();
hashMap.put("1", "good");
hashMap.put("2", "study");
hashMap.put("3", "day");
hashMap.put("4", "up");
for (Map.Entry<String, String> entry : hashMap.entrySet()) {
? ? System.out.println(entry.getKey()+":"+entry.getValue());
}2.使用foreach迭代鍵值對
Map<String, String> hashMap = new HashMap<String,String>();
hashMap.put("1", "good");
hashMap.put("2", "study");
hashMap.put("3", "day");
hashMap.put("4", "up");
for (String key : hashMap.keySet()) {
? ? System.out.println(key);
}
for (String value : hashMap.values()) {
? ? System.out.println(value);
}3.使用迭代器
Map<String, String> hashMap = new HashMap<String,String>();
hashMap.put("1", "good");
hashMap.put("2", "study");
hashMap.put("3", "day");
hashMap.put("4", "up");
Iterator<Map.Entry<String, String>> iterator = hashMap.entrySet().iterator();
while (iterator.hasNext()) {
? ? Map.Entry<String, String> next = iterator.next();
? ? System.out.println(next.getKey()+":"+next.getValue());
}4.使用lambda表達(dá)式
Map<String, String> hashMap = new HashMap<String,String>();
hashMap.put("1", "good");
hashMap.put("2", "study");
hashMap.put("3", "day");
hashMap.put("4", "up");
hashMap.forEach((k,v)-> System.out.println(k+":"+v));相同點(diǎn):
都是實(shí)現(xiàn)來Map接口(hashTable還實(shí)現(xiàn)了Dictionary 抽象類)。
不同點(diǎn):
1. 歷史原因:Hashtable 是基于陳舊的 Dictionary 類的,HashMap 是 Java 1.2 引進(jìn)的 Map 接口
的一個(gè)實(shí)現(xiàn),HashMap把Hashtable 的contains方法去掉了,改成containsvalue 和containsKey。因?yàn)閏ontains方法容易讓人引起誤解。
2. 同步性:Hashtable 的方法是 Synchronize 的,線程安全;而 HashMap 是線程不安全的,不是同步的。所以只有一個(gè)線程的時(shí)候使用hashMap效率要高。
3. 值:HashMap對象的key、value值均可為null。HahTable對象的key、value值均不可為null。
4. 容量:HashMap的初始容量為16,Hashtable初始容量為11,兩者的填充因子默認(rèn)都是0.75。
5. HashMap擴(kuò)容時(shí)是當(dāng)前容量翻倍即:capacity * 2,Hashtable擴(kuò)容時(shí)是容量翻倍+1 即:capacity * 2+1。
HashSet 底層就是基于 HashMap 實(shí)現(xiàn)的。只不過HashSet里面的HashMap所有的value都是同一個(gè)Object而已,因此HashSet也是非線程安全的。

1. HashMap通過hashcode對其內(nèi)容進(jìn)行快速查找,而TreeMap中所有的元素都保持著某種固定的順序,如果你需要得到一個(gè)有序的結(jié)果你就應(yīng)該使用TreeMap(HashMap中元素的排列順序是不固定的)。
2. 在Map 中插入、刪除和定位元素,HashMap是最好的選擇。但如果您要按自然順序或自定義順序遍歷鍵,那么TreeMap會更好。使用HashMap要求添加的鍵類明確定義了hashCode()和 equals()的實(shí)現(xiàn)。
每當(dāng)向數(shù)組中添加元素時(shí),都要去檢查添加后元素的個(gè)數(shù)是否會超出當(dāng)前數(shù)組的長度,如果超出,數(shù)組將會進(jìn)行擴(kuò)容,以滿足添加數(shù)據(jù)的需求。數(shù)組擴(kuò)容通過ensureCapacity(int minCapacity)方法來實(shí)現(xiàn)。在實(shí)際添加大量元素前,我也可以使用ensureCapacity來手動增加ArrayList實(shí)例的容量,以減少遞增式再分配的數(shù)量。 數(shù)組進(jìn)行擴(kuò)容時(shí),會將老數(shù)組中的元素重新拷貝一份到新的數(shù)組中,每次數(shù)組容量的增長大約是其原容量的1.5倍。這種操作的代價(jià)是很高的,因此在實(shí)際使用時(shí),我們應(yīng)該盡量避免數(shù)組容量的擴(kuò)張。當(dāng)我們可預(yù)知要保存的元素的多少時(shí),要在構(gòu)造ArrayList實(shí)例時(shí),就指定其容量,以避免數(shù)組擴(kuò)容的發(fā)生。或者根據(jù)實(shí)際需求,通過調(diào)用ensureCapacity方法來手動增加ArrayList實(shí)例的容量。
ArrayList也采用了快速失敗的機(jī)制,通過記錄modCount參數(shù)來實(shí)現(xiàn)。在面對并發(fā)的修改時(shí),迭代器很快就會完全失敗,而不是冒著在將來某個(gè)不確定時(shí)間發(fā)生任意不確定行為的風(fēng)險(xiǎn)。

官方微信

官方抖音










 京公網(wǎng)安備 11030102010736號
京公網(wǎng)安備 11030102010736號