索引其實是一種數(shù)據(jù)結(jié)構(gòu),能夠幫助我們快速的檢索數(shù)據(jù)庫中的數(shù)據(jù)。
首先數(shù)據(jù)是以文件的形式存放在磁盤上面的,每一行數(shù)據(jù)都有它的磁盤地址。如果沒有索引的話,要從500萬行數(shù)據(jù)里面檢索一條數(shù)據(jù),只能依次遍歷這張表的全部數(shù)據(jù),直到找到這條數(shù)據(jù)。但是有了索引之后,只需要在索引里面去檢索這條數(shù)據(jù)就行了,因為它是一種特殊的專門用來快速檢索的數(shù)據(jù)結(jié)構(gòu),我們找到數(shù)據(jù)存放的磁盤地址以后,就可以拿到數(shù)據(jù)了。就像我們從一本 500 頁的書里面去找特定的一小節(jié)的內(nèi)容,肯定不可能從第一頁開始翻。那么這本書有專門的目錄,它可能只有幾頁的內(nèi)容,它是按頁碼來組織的,可以根據(jù)拼音或者偏旁部首來查找,只要確定內(nèi)容對應(yīng)的頁碼,就能很快地找到我們想要的內(nèi)容。
優(yōu)點
● 提高數(shù)據(jù)檢索的效率,降低數(shù)據(jù)庫IO成本。
● 通過索引對數(shù)據(jù)進行排序,降低數(shù)據(jù)的排序成本,降低CPU的消耗。
缺點
● 建立索引需要占用物理空間
● 會降低表的增刪改的效率,因為每次對表記錄進行增刪改,需要進行動態(tài)維護索引,導(dǎo)致增刪改時間變長
需要建索引的情況
1. 主鍵自動創(chuàng)建唯一索引
2. 較頻繁的作為查詢條件的字段
3. 查詢中排序的字段,查詢中統(tǒng)計或者分組的字段
不需要建索引的情況
1. 表記錄太少的字段
2. 經(jīng)常增刪改的字段
3. 唯一性太差的字段,不適合單獨創(chuàng)建索引。比如性別,民族,政治面貌
索引的數(shù)據(jù)結(jié)構(gòu)是B+樹(加強版多路平衡查找樹),原理:如下圖,是一顆B+樹,淺藍色的塊我們稱之為一個磁盤塊,可以看到每個磁盤塊包含幾個數(shù)據(jù)項(深藍色所示)和指針(黃色所示),如磁盤塊1包含數(shù)據(jù)項17和35,包含指針P1、P2、P3,P1表示小于17的磁盤塊,P2表示在17和35之間的磁盤塊,P3表示大于35的磁盤塊。真實的數(shù)據(jù)存在于葉子節(jié)點即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非葉子節(jié)點只不存儲真實的數(shù)據(jù),只存儲指引搜索方向的數(shù)據(jù)項,如17、35并不真實存在于數(shù)據(jù)表中。
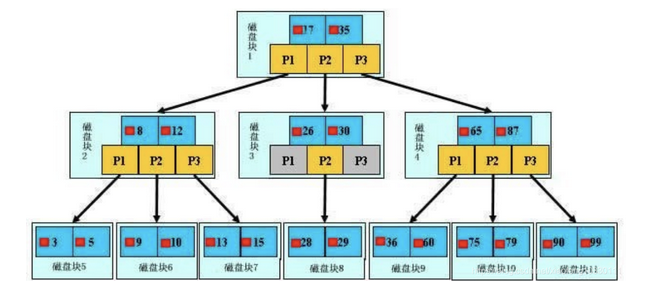
查找過程:如圖所示,如果要查找數(shù)據(jù)項29,那么首先會把磁盤塊1由磁盤加載到內(nèi)存,此時發(fā)生一次IO,在內(nèi)存中用二分查找確定29在17和35之間,鎖定磁盤塊1的P2指針,內(nèi)存時間因為非常短(相比磁盤的IO)可以忽略不計,通過磁盤塊1的P2指針的磁盤地址把磁盤塊3由磁盤加載到內(nèi)存,發(fā)生第二次IO,29在26和30之間,鎖定磁盤塊3的P2指針,通過指針加載磁盤塊8到內(nèi)存,發(fā)生第三次IO,同時內(nèi)存中做二分查找找到29,結(jié)束查詢,總計三次IO。真實的情況是,3層的b+樹可以表示上百萬的數(shù)據(jù),如果上百萬的數(shù)據(jù)查找只需要三次IO,性能提高將是巨大的,如果沒有索引,每個數(shù)據(jù)項都要發(fā)生一次IO,那么總共需要百萬次的IO,顯然成本非常非常高。
優(yōu)點:保證等值和范圍查詢的快速查找。
先來說說二叉查找樹(BST Binary Search Tree),二叉查找樹在數(shù)組和鏈表的基礎(chǔ)上整合出來的一個新的數(shù)據(jù)結(jié)構(gòu)。
1. 二叉查找樹(BST Binary Search Tree)
二叉查找樹的特點是左子樹所有的節(jié)點都小于父節(jié)點,右子樹所有的節(jié)點都大于父節(jié)點。投影到平面以后,就是一個有序的線性表。
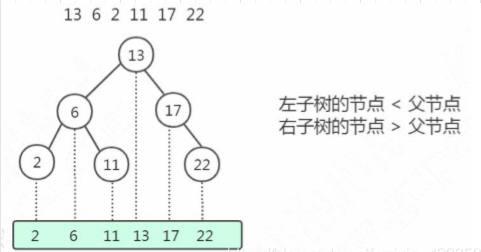
比如我們插入的數(shù)據(jù)是有序的[2、6、11、13、17、22] ,那么這個時候我們的二叉查找樹變成了什么樣了呢?如下圖:
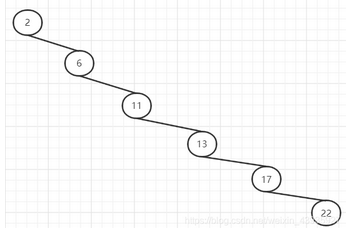
很明顯,樹變成鏈表了,因為左右子樹深度差太大,這棵樹的左子樹根本沒有節(jié)點——也就是它不夠平衡。
優(yōu)點:能夠?qū)崿F(xiàn)快速查找和插入。
缺點:樹的深度會影響查找效率。
1. 平衡二叉樹(Balanced binary search trees)
平衡二叉樹又稱紅黑樹,除了具備二叉樹的特點,最主要的特征是左右子樹深度差絕對值不能超過1。例如我們按順序插入1、2、3、4、5、6,就會變成如下圖:
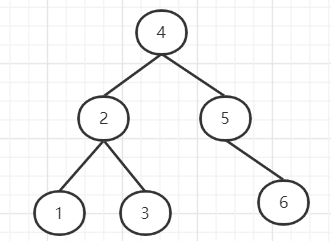
優(yōu)點:在插入刪除數(shù)據(jù)時通過左旋/右旋操作保持二叉樹的平衡,不會出現(xiàn)左子樹很高、右子樹很矮的情況。
缺點:
● 時間復(fù)雜度和樹高相關(guān)。樹有多高就需要檢索多少次,每個節(jié)點的讀取,都對應(yīng)一次磁盤 IO 操作。樹的高度就等于每次查詢數(shù)據(jù)時磁盤 IO 操作的次數(shù)。在表數(shù)據(jù)量大時,查詢性能就會很差。
● 平衡二叉樹不支持快速的范圍查找,范圍查找時需要從根節(jié)點多次遍歷,查詢效率不高。
1)單列索引:一個索引只包含單個列,但一個表中可以有多個單列索引。
主鍵索引:主鍵是一種唯一性索引,但它必須指定為PRIMARY KEY,每個表只能有一個主鍵。
唯一索引:索引列的所有值都只能出現(xiàn)一次,即必須唯一,值可以為空。
CREATE UNIQUE INDEX account_UNIQUE_Index ON `award`(`account`);
普通索引:基本的索可以為空,沒有唯一性的限制。
CREATE INDEX account_Index ON `award`(`account`);
2)復(fù)合索引:
符合索引遵循索引最左匹配原則,舉例:創(chuàng)建一個(a,b)的聯(lián)合索引,那么它的索引樹就是下圖的樣子。
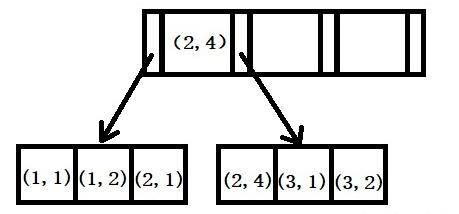
可以看到a的值是有順序的,1,1,2,2,3,3,而b的值是沒有順序的1,2,1,4,1,2。但是我們又可發(fā)現(xiàn)a在等值的情況下,b值又是按順序排列的,但是這種順序是相對的。這是因為MySQL創(chuàng)建聯(lián)合索引的規(guī)則是首先會對聯(lián)合索引的最左邊第一個字段排序,在第一個字段的排序基礎(chǔ)上,然后在對第二個字段進行排序。
復(fù)合索引是包含兩個或兩個以上字段的索引。
create index a_b_c_index on table1(a,b,c)
創(chuàng)建的聯(lián)合索引a_b_c_index,實際上相當(dāng)于建立了三個索引(a)、(a_b)、(a_b_c)。
注意:
● 查詢必須從索引的最左邊的列開始,否則無法使用索引。比如直接使用b或著c,此時索引會失效。
● 查詢不能跳過某一個索引。比如使用了a索引,但是跳過了b,使用了c,此時只有a索引有用,而c索引失效。
● 查詢中如果使用了范圍查詢,那么其右側(cè)的索引列會失效。比如a=1 and b>2 and c=3.此時b使用了范圍查詢,>、like等。c索引列不會起作用。
3) 全文索引
全文索引,只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT類型字段上使用全文索引,介紹了要求,說說什么是全文索引,就是在一堆文字中,通過其中的某個關(guān)鍵字等,就能找到該字段所屬的記錄行,比如有"我愛學(xué)編程尤其是java ..." 通過java,可能就可以找到該條記錄。這里說的是可能,因為全文索引的使用涉及了很多細節(jié),我們只需要知道這個大概意思。一般開發(fā)中,不貴用到全文索引,因為其占用很大的物理空間和降低了記錄修改性,故較為少用。
在查詢sql前面加一個explain,如explain select ..........
 我們只需要注意一個最重要的type 的信息很明顯的提現(xiàn)是否用到索引,type結(jié)果值從好到壞依次是:
我們只需要注意一個最重要的type 的信息很明顯的提現(xiàn)是否用到索引,type結(jié)果值從好到壞依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般來說,得保證查詢至少達到range級別,最好能達到ref,否則就可能會出現(xiàn)性能問題。其中possible_keys:sql所用到的索引
聚簇索引就是將數(shù)據(jù)(一行一行的數(shù)據(jù))跟索引結(jié)構(gòu)放到一塊,innodb存儲引擎使用的就是聚簇索引;聚集索引中表記錄的排列順序和索引的排列順序一致,所以查詢效率快,只要找到第一個索引值記錄,其余就連續(xù)性的記錄在物理也一樣連續(xù)存放。聚集索引對應(yīng)的缺點就是修改慢,因為為了保證表中記錄的物理和索引順序一致,在記錄插入的時候,會對數(shù)據(jù)頁重新排序。
而非聚集索引:制定了表中記錄的邏輯順序,但是記錄的物理和索引不一定一致,兩種索引都采用B+樹結(jié)構(gòu),非聚集索引的葉子層并不和實際數(shù)據(jù)頁相重疊,而采用葉子層包含一個指向表中的記錄在數(shù)據(jù)頁中的指針方式。非聚集索引層次多,不會造成數(shù)據(jù)重排。
1.由于行數(shù)據(jù)和聚簇索引的葉子節(jié)點存儲在一起,同一頁(16k)中會有多條行數(shù)據(jù),訪問同一數(shù)據(jù)頁不同行記錄時,已經(jīng)把頁加載到了Buffer中(讀取數(shù)據(jù)是按頁讀取的),再次訪問時,會在內(nèi)存中完成訪問,不必訪問磁盤。這樣主鍵和行數(shù)據(jù)是一起被載入內(nèi)存的,找到葉子節(jié)點就可以立刻將行數(shù)據(jù)返回了,如果按照主鍵Id來組織數(shù)據(jù),獲得數(shù)據(jù)更快。
2.輔助索引的葉子節(jié)點,存儲主鍵值,而不是數(shù)據(jù)的存放地址。好處是當(dāng)行數(shù)據(jù)放生變化時,索引樹的節(jié)點也需要分裂變化;或者是我們需要查找的數(shù)據(jù),在上一次IO讀寫的緩存中沒有,需要發(fā)生一次新的IO操作時,可以避免對輔助索引的維護工作,只需要維護聚簇索引樹就好了。另一個好處是,因為輔助索引存放的是主鍵值,減少了輔助索引占用的存儲空間大小。
3.因為MyISAM的主索引并非聚簇索引,那么他的數(shù)據(jù)的物理地址必然是凌亂的,拿到這些物理地址,按照合適的算法進行I/O讀取,于是開始不停的尋道不停的旋轉(zhuǎn)。聚簇索引則只需一次I/O。不過,如果涉及到大數(shù)據(jù)量的排序、全表掃描、count之類的操作的話,還是MyISAM占優(yōu)勢些,因為索引所占空間小,這些操作是需要在內(nèi)存中完成的。
主鍵最好不要使用uuid,因為uuid的值太過離散,不適合排序且可能出現(xiàn)新增加記錄的uuid,會插入在索引樹中間的位置,出現(xiàn)頁分裂(比如之前的索引已經(jīng)緊湊的排列在一起了,你此時需要在已經(jīng)緊湊排列好的數(shù)據(jù)中插入數(shù)據(jù)就會導(dǎo)致前面已經(jīng)排好序的索引出現(xiàn)松動和重構(gòu)排序,但是使用自增id就不會出現(xiàn)這種情況了),導(dǎo)致索引樹調(diào)整復(fù)雜度變大,消耗更多的時間和資源。但是使用自增主鍵就可以避免出現(xiàn)頁分裂,因為自增主鍵后面的主鍵值是要比前面的大, 那后來的數(shù)據(jù)直接放在后面就行;
聚簇索引的數(shù)據(jù)的物理存放順序與索引順序是一致的,即:只要索引是相鄰的,那么對應(yīng)的數(shù)據(jù)一定也是相鄰地存放在磁盤上的。如果主鍵不是自增id,它會不斷地調(diào)整數(shù)據(jù)的物理地址、分頁,當(dāng)然也有其他一些措施來減少這些操作,但卻無法徹底避免。但如果是自增的id,它只需要一 頁一頁地寫,索引結(jié)構(gòu)相對緊湊,磁盤碎片少,效率也高。
如果一個查詢是先走輔助索引(聚簇索引外的索引都叫輔助索引)的,那么通過這個輔助索引(innodb中的輔助索引的data存儲的是主鍵)沒有獲取到我們想要的全部數(shù)據(jù),那么MySQL就會拿著輔助索引查詢出來的主鍵去聚簇索引中進行查詢,這個過程就是叫回表;
所謂的索引覆蓋是索引高效找到行的一個方法,當(dāng)能通過檢索索引就可以讀取想要的數(shù)據(jù),那就不需要再到數(shù)據(jù)表中讀取行了。如果一個索引包含了(或覆蓋了)滿足查詢語句中字段與條件的數(shù)據(jù)就叫做覆蓋索引。
============
注意:id 字段是聚簇索引,age 字段是普通索引(二級索引)
select id,age from user where age = 30;
上面的這個sql是不用回表查詢的,因為在非聚簇索引的葉子節(jié)點上已經(jīng)有id和age的值。所以根本不需要拿著id的值再去聚簇索引定位行記錄數(shù)據(jù)了。也就是在這一顆索引樹上就可以完成對數(shù)據(jù)的檢索,這樣就實現(xiàn)了覆蓋索引。
select id,age,name from user where age = 30;
而上面的這個sql不能實現(xiàn)索引覆蓋了,因為name的值在age索引樹上是沒有的,還是需要拿著id的值再去聚簇索引定位行記錄數(shù)據(jù)。但是如果我們對age和name做一個組合索引idx_age_name(age,name),那就又可以實現(xiàn)索引覆蓋了。
1)like查詢以%開頭,因為會導(dǎo)致查詢出來的結(jié)果無序;如:應(yīng)盡量避免使用模糊查詢, like "xxxx%" 是可以用到索引的,like "%xxxx" 則不行(like "%xxx%" 同理)。否則將導(dǎo)致引擎將放棄使用索引而進行全表掃描。
2)類型轉(zhuǎn)換,列計算也會可能會讓索引失效,因為結(jié)果可能是無序的,也可能是有序的;如:應(yīng)盡量避免在where子句中的“=”左邊進行函數(shù)、算術(shù)運算或其他表達式運算,否則將導(dǎo)致引擎放棄使用索引而進行全表掃描。如:select id from t where num/2=100應(yīng)改為:select id from t where num=100*2
3)在一些查詢的語句中,MySQL認為走全表掃描也會導(dǎo)致索引失效;如:應(yīng)盡量避免使用is null 和is not null 、in和not in,否則將導(dǎo)致引擎將放棄使用索引而進行全表掃描。
對于連續(xù)的數(shù)值用between就不要用in,如:select id from t where num in(1,2,3) 替換成:select id from t where num between 1 and 3
用exists代替in,如:select num from a where num in(select num from b) 替換成:select num from a where exists(select 1 from b where num=a.num)
4)如果條件中有or并且or連接的字段中有列沒有索引,那么即使其中有條件帶索引也不會使用索引 (這是因為MySQL判斷即便你開始走了索引查詢,但是它發(fā)現(xiàn)查詢中有or ,也就是說or 后面的還是需要走全表掃描(因為or會導(dǎo)致后面的數(shù)據(jù)是無序的),所以MySQL還不如一開始就直接走全表掃描,這也是為什么盡量少用or的原因)要想使用or,又想讓索引生效,只能將or條件中的每個列都加上索引,當(dāng)檢索條件有or但是所有的條件都有索引時,索引不失效,可以走【兩個索引】,這叫索引合并(取二者的并集);
5)復(fù)合索引不滿足最左原則就不能使用全部索引,如:注意最佳左前綴法則,比如建立了一個聯(lián)合索引(a,b,c),那么其實我們可利用的索引就有(a), (a,b), (a,b,c)。
索引的b+樹結(jié)構(gòu),為什么使用b+樹說一下,然后再說一下聚簇索引,回表和索引覆蓋;
然后再談一下索引失效;

官方微信

官方抖音










 京公網(wǎng)安備 11030102010736號
京公網(wǎng)安備 11030102010736號